VLM综述
综述
Vision-Language Models for Vision Tasks: A Survey(综述)
- 新范式:预训练-微调-预测 需要任务特化的微调
- 新范式:视觉语言模型预训练(大量图像文本对)和zero-shot预测(直接运用到下游的视觉识别任务)
预训练时设计一个视觉-语言目标,使模型能学习到视觉语言的相关性(CLIP使用对比方法拉进图像文本对) - 两个研究方向:
- 迁移学习:有效的使预训练模型适应下游任务
- 知识蒸馏:蒸馏预训练模型的知识适配下游任务
- 发展:
- 预训练目标:从单一目标(对比)到多种目标融合(对比、对齐、生成)
- 预训练框架:从独立网络(双塔结构)到统一网络
- 下游任务:从简单到复杂
- image encoder:CNN-based(VGG,ResNet)或Transformer-based(ViT)
- text encoder:标准transformer
- VLM预训练目标:
- 对比目标:拉进正对,推开负对
目的:学会区分不同的图像-文本特征,学习图像-文本特征的联系
损失函数:余弦相似度(点乘) - 生成目标:生成图片、文字数据
目的:学习语义知识- 图片生成:随机遮掩一系列图片patch,训练解码器通过未遮掩的patch重建图片
- 文字生成(完形填空):
- 交叉生成:一对图像文本对,随机遮掩图片patch和文本token,学习重建它们
- 图文生成:自回归的预测文本
- 对齐目标:
目的:对齐图像和文本,因较为简单常作为辅助手段- 图文配对:表示图文对齐可能性,,为1如果配对
- 区域-单词配对:将图文对变成区域单词对,其他同上
- 下游任务
- 图片分类
通过prompt engineering构造“a photo of a [label].”这样的句子 - 语义分割
比较图片每个像素和句子的嵌入 - 目标检测
比较给出的object proposals和句子 - 图片-文本推理
通过图像检索文本,通过文本检索图像
- 图片分类
- 对比目标:拉进正对,推开负对
- VLM迁移学习:
- 目的:调整VLM适配下游任务
- 预训练模型执行下游任务的问题:
- 图文分布不同
- 训练目标不同(预训练目标是任务无关的)
- 指令微调
prompt learning
不微调VLM模型,寻找优化的prompt
优点:易于实现,只加入少量可学习的参数
分类:- 文本指令微调
类似CoOp那种在text的标签前加上可被学习的参数
使用一些下游任务例子,最小化分类loss(few shot) - 视觉指令微调
为图像加上一个可训练的扰动,达到像素级的适配
- 文本指令微调
- 特征适配
目的:通过一个轻量的特征适配器微调VLM去适配图像文本特征
上述两种都是few shot微调 - 其他方法:直接微调、修改架构、交叉注意力
- VLM知识蒸馏:
蒸馏VLM的知识处理复杂困难的任务比如目标识别和语义分割,架构采用与任务适配的模型
将图像层面的表现迁移到区域或像素层面的任务上- 为目标检测的知识蒸馏
目的:扩大检测范围(词汇量)
ViLD让检测器的嵌入空间相似与CLIP图像编码器的嵌入空间
使用VLM预测出的伪标签提高目标检测器的预测能力 - 为语义分割的知识蒸馏
目的:利用VLM的零样本能力实现开放词汇表的语义分割(LSeg)
- 另一种分类方式:
- 特征空间蒸馏:使检测/分割的嵌入和VLM的嵌入一致
- 伪标签蒸馏:VLM生成伪标签指导检测/分割模型
- 为目标检测的知识蒸馏
经典论文
CLIP及后续工作
CLIP(Contrastive Language-Image Pre-Training)
https://arxiv.org/pdf/2103.00020
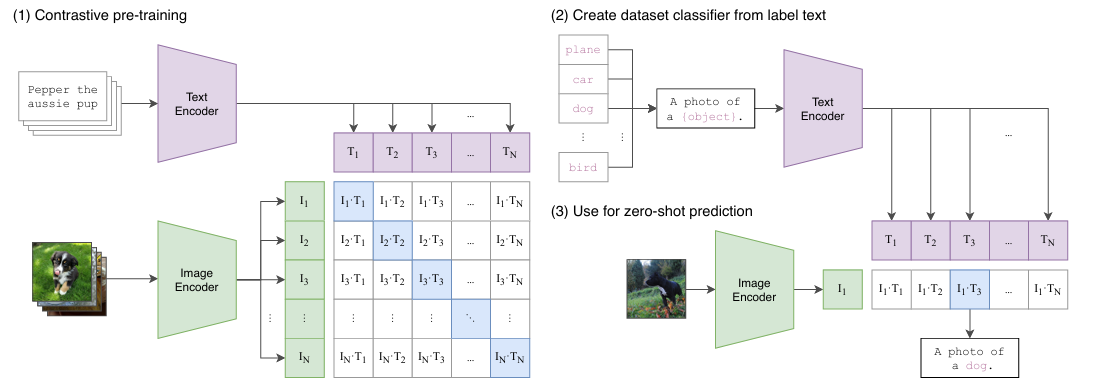
- 多模态预训练神经网络
- 对齐text模态和image模态(余弦相似度:最大化真实对,最小化错误对),使用图像文本对进行训练,对比学习(无监督)
- 图像编码器采用ViT或ResNet50架构,文本编码器采用Transformer架构
- 具备zero shot能力(能够直接在未见过的任务或类别上进行推理和分类,而无需针对特定任务的标注数据进行微调)
LSeg(Language-driven Semantic Segmentation)
https://arxiv.org/pdf/2201.03546
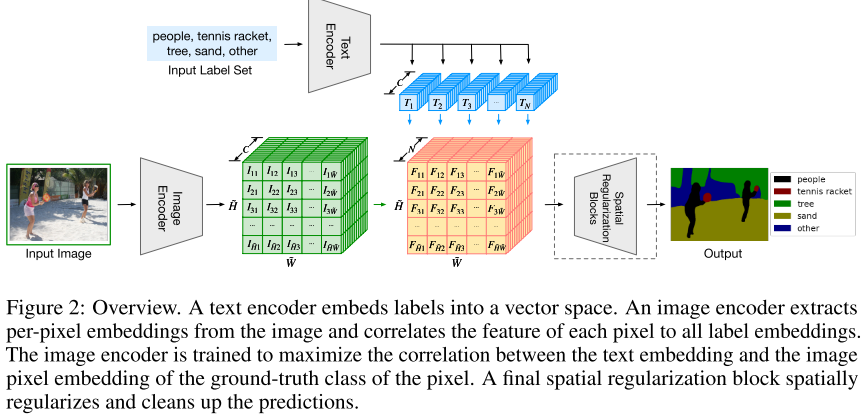
- 使用CLIP架构完成语义分割任务
- image encoder:dpt结构(ViT+decoder(升维))得到特征图
- 文本:输入n个lable,经编码器(冻结)得到n个特征
- 有监督的训练:输出和ground truth musk(掩码标签)做cross entrophy loss
- 将文本这一支加入传统有监督学习的pipeline中,能使用text prompt任意得到分割效果
GroupViT
https://arxiv.org/pdf/2202.11094

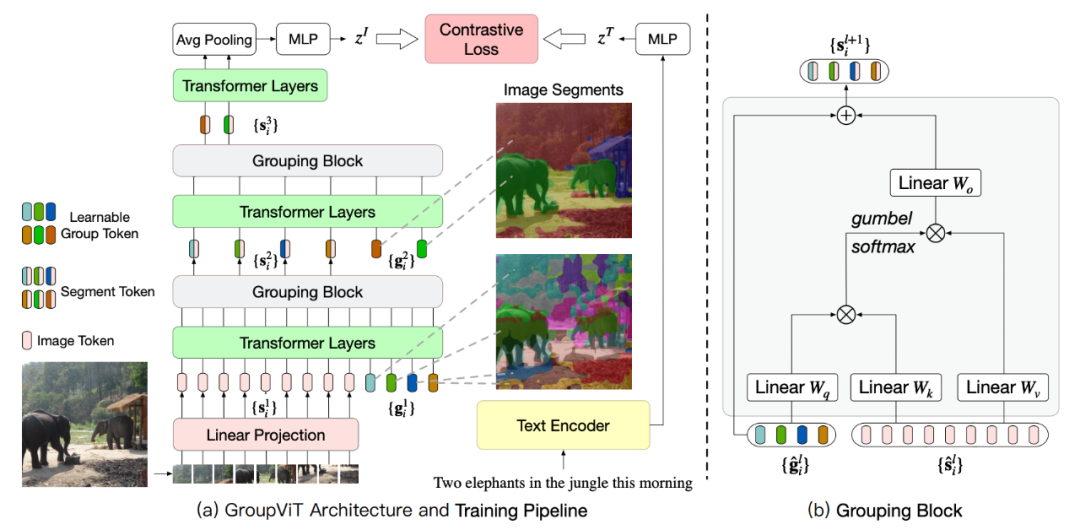
- 不使用手工标注,使用纯文本监督学习一个语义分割模型
- grouping方法:从聚类中心点到mask
加入grouping block和group tokens - 训练:64类->8类->一个特征,同text特征做contrastive loss
- 推理:image->8个特征->同text特征算余弦相似度,高的为对应类
ViLD(Open-Vocabulary Object Detection via Vision and Language Konwledge Distillation)
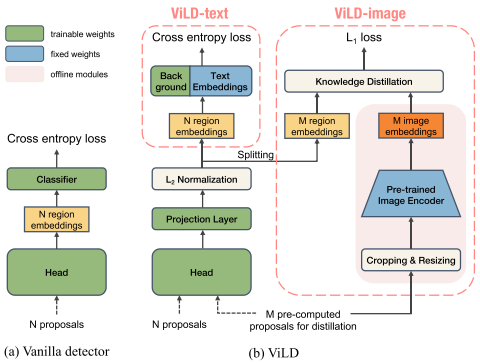
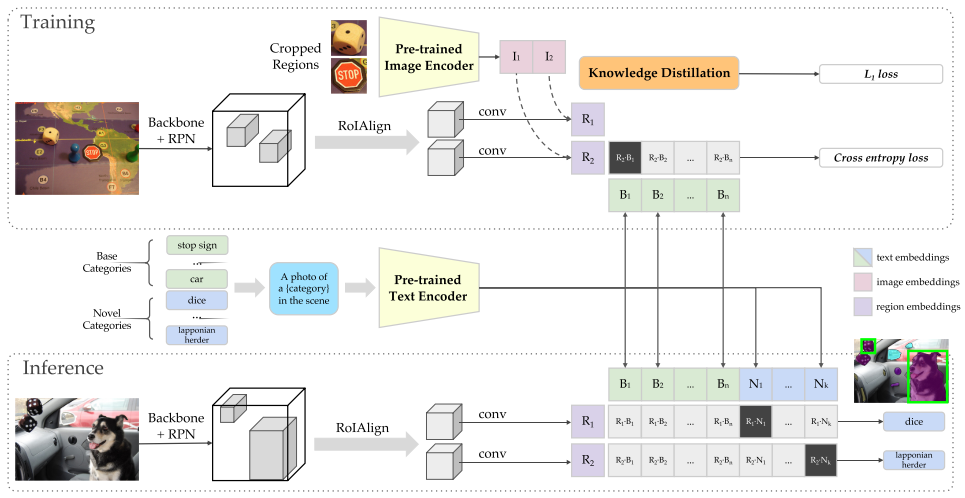
- 蒸馏CLIP
- ViLD-text:图像特征(N region embeddings)同文本特征计算cross entopy loss
- 有监督训练(text使用基础类)zero shot能力不好
- ViLD-image:增加zero shot能力->让图片特征接近CLIP输出的图片特征(蒸馏)
GLIP(Grounded Language-Image Pre-training)
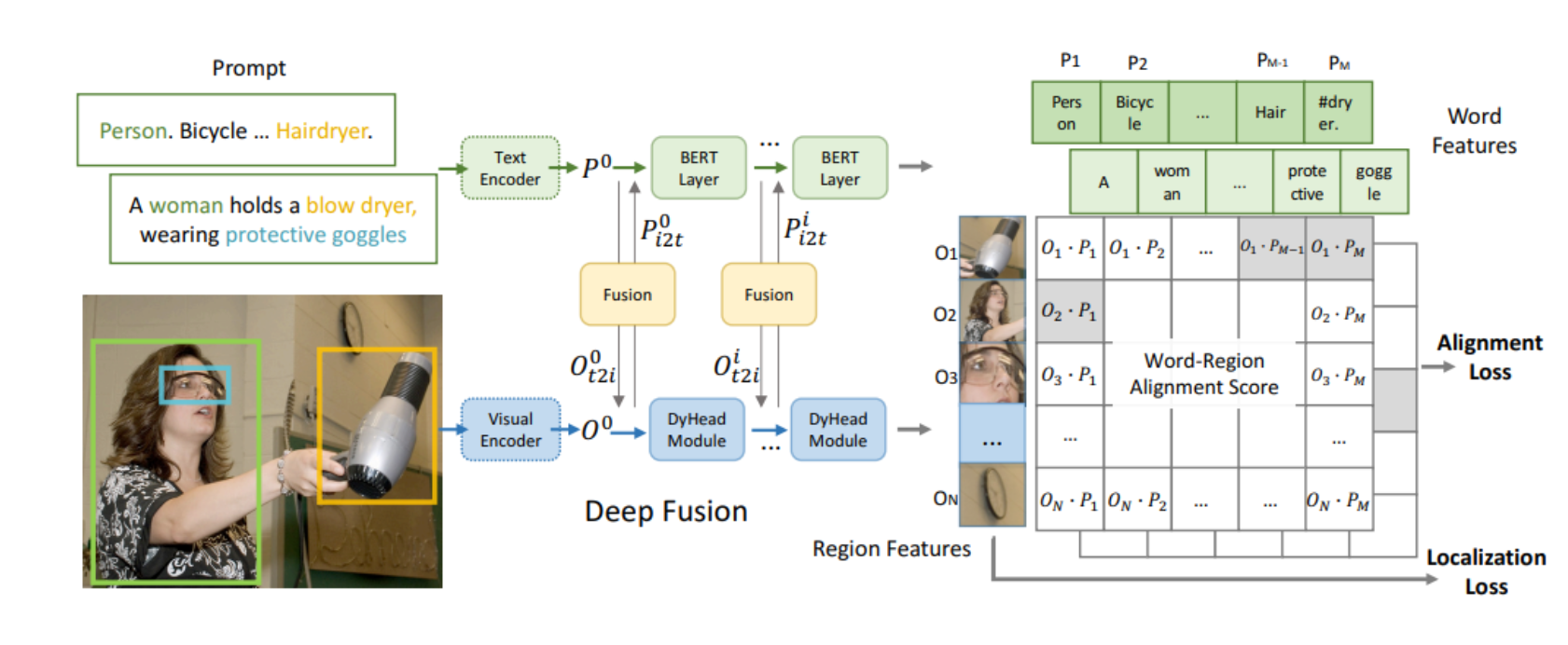
- 合并detection和phase grounding任务
- 图像编码器和语言编码器间的深度融合(图中fusion->使用多头交叉注意力)
- 语义:Alignment loss 定位:Localization loss
- 有监督学习,具备zero shot性能
CLIPasso(Semanically-Aware Object Skeching)
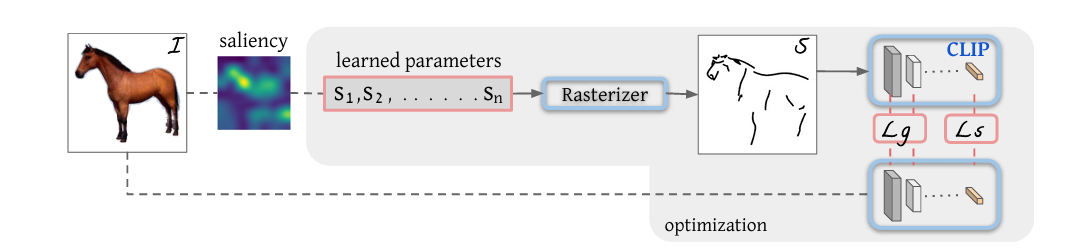
- 笔画使用四个点生成-贝兹曲线(Bezier Curve)
- 图片-采样(更好的初始化)-笔画-光栅化器(Rasterizer),可导-简笔画
- 训练:简笔画和原图经CLIP得到的特征尽可能近();使用网络前几层输出做loss保证几何形状相似()
CLIP4Clip,ActionCLIP
视频相关
AudioCLIP
text、image、audio两两CLIP
PointCLIP
3D vision
DepthCLIP
感知深度
后续多模态
ALBEF(Align before Fuse: Vision and Language Representation Learning with Momentum Distillation)
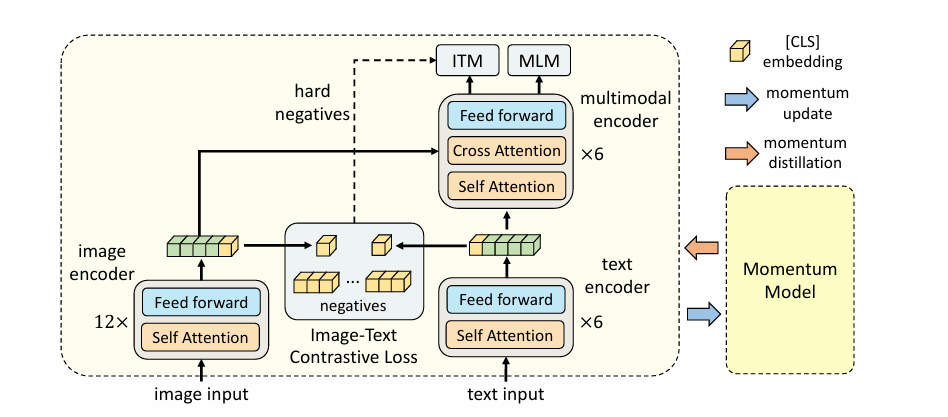
- 视觉端比较大,文字端尽量小,融合部分尽量大的模型是好的
- loss选择:ITC(相似度,align)+ITM(是否为正样本对)+MLM(完形填空)
- 视觉端:12层ViT
- 文字端:BERT的一半
- 模态融合:BERT的另一半
- 其他工作:动量蒸馏提升数据质量 hard negatives:负样本中相似度最高的
VLMo
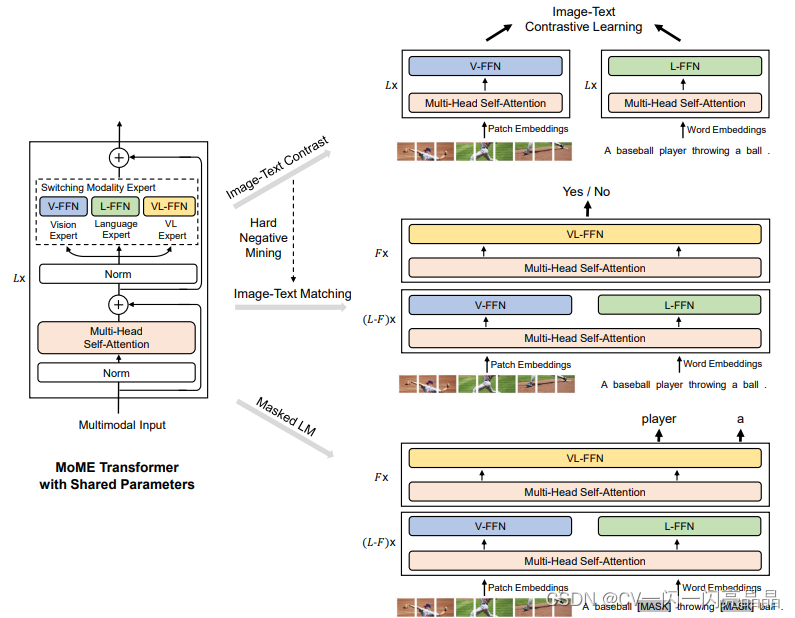
BLIP(Bootstrapping Language-Image Pre-training)
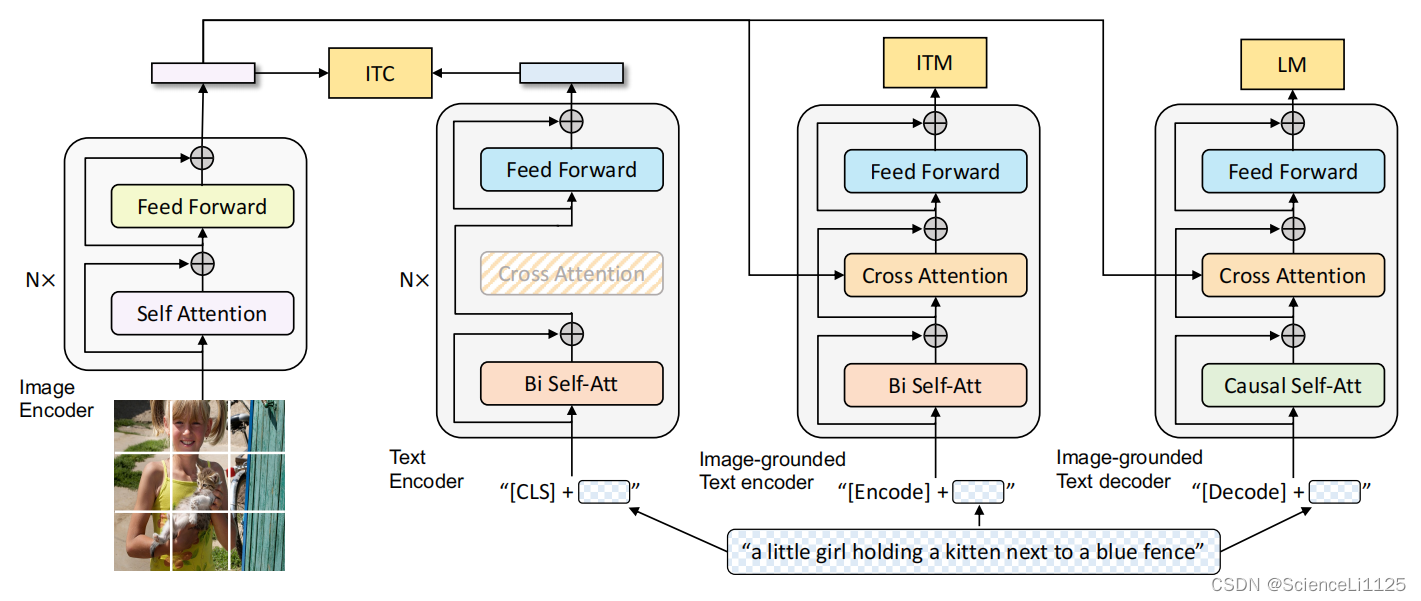
- 可以做生成任务
- 图像端:完整的ViT
- 文本端:三个
- 图像端+前两个文本端构成ALBEF(self attention层共享参数)
- 第三个文本端:Decode,做生成任务(Causal Self-Att 因果自注意力)
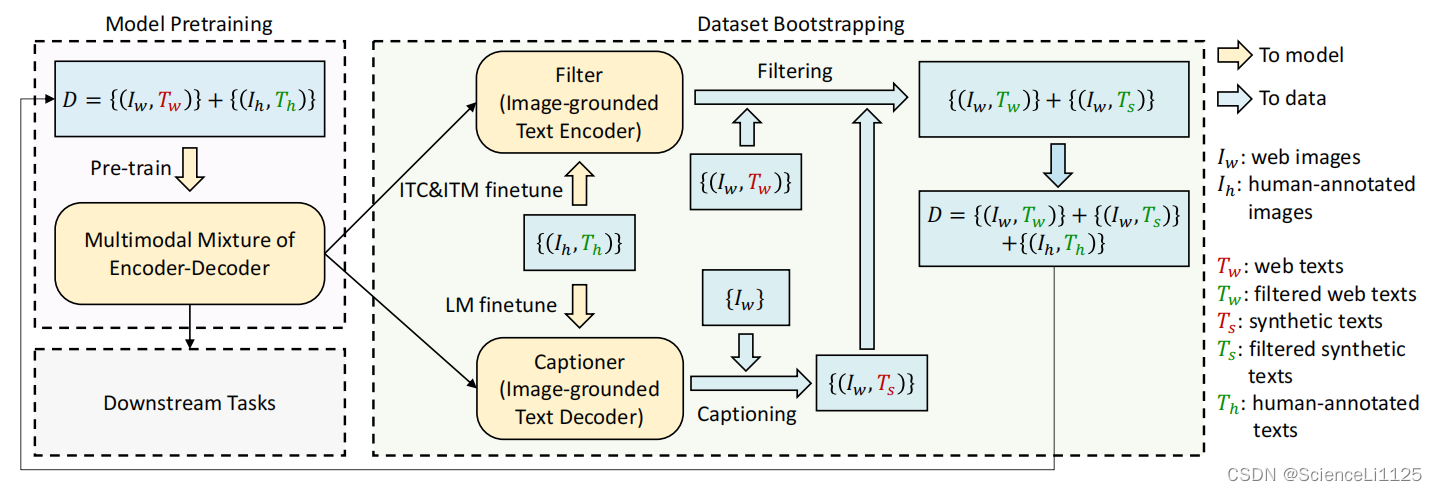
- capfilt model:
- 作用:生成更好的数据
- 干净的数据集对训练好的BLIP中的第二个文本端(做Filter)和第三个文本端(做Captioner)做微调
- 网上数据集输入Filter计算是否匹配过滤
- decoder生成一个更好的文本
CoCa(Contrastive Captioners are Image-Text Foundation Models)
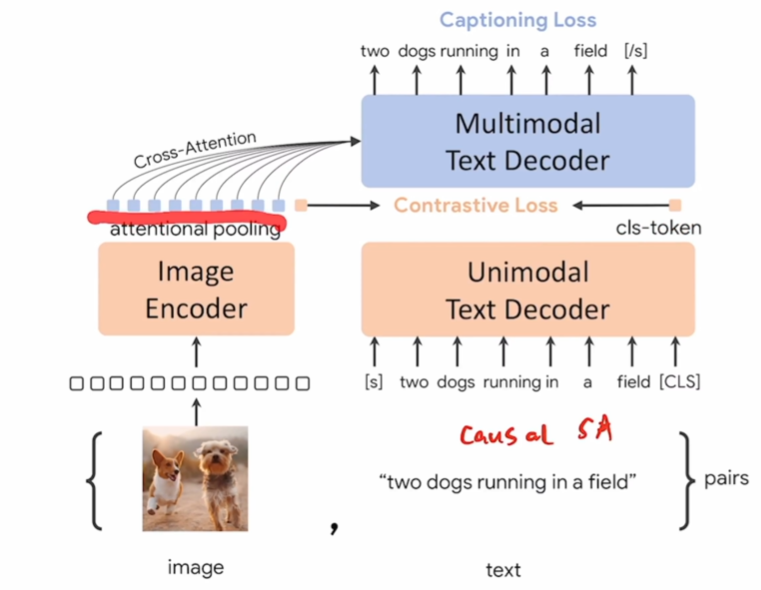
- 两个loss:Contrastive Loss和Captioning Loss
- 模型结构类似ALBEF
- 图像做attention pooling 可学习
- 文本使用decoder
BeiT(image as a Foreign Language)大统一
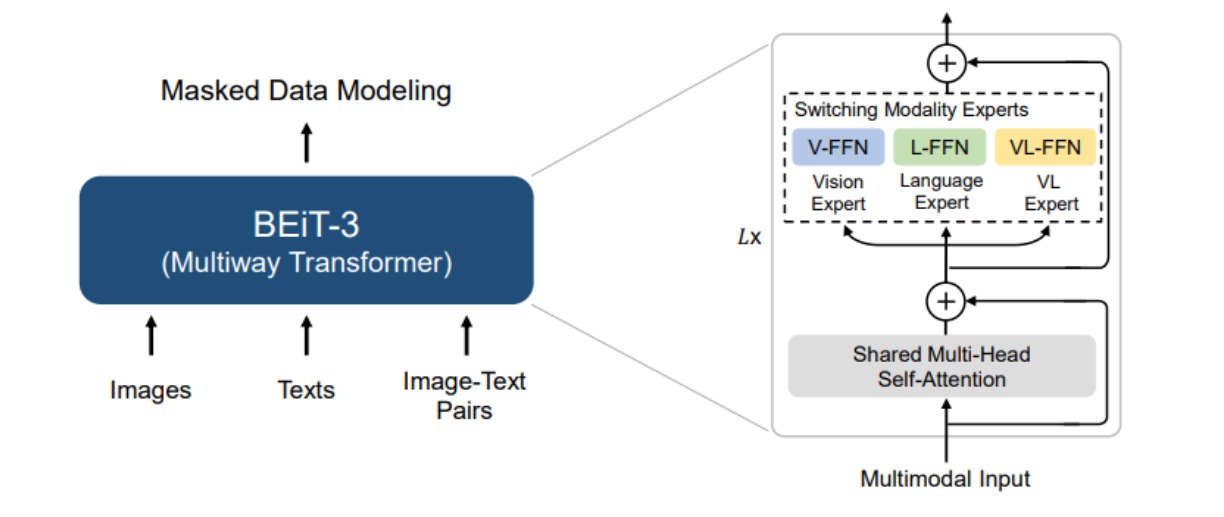
- Multiway Transformer MoME
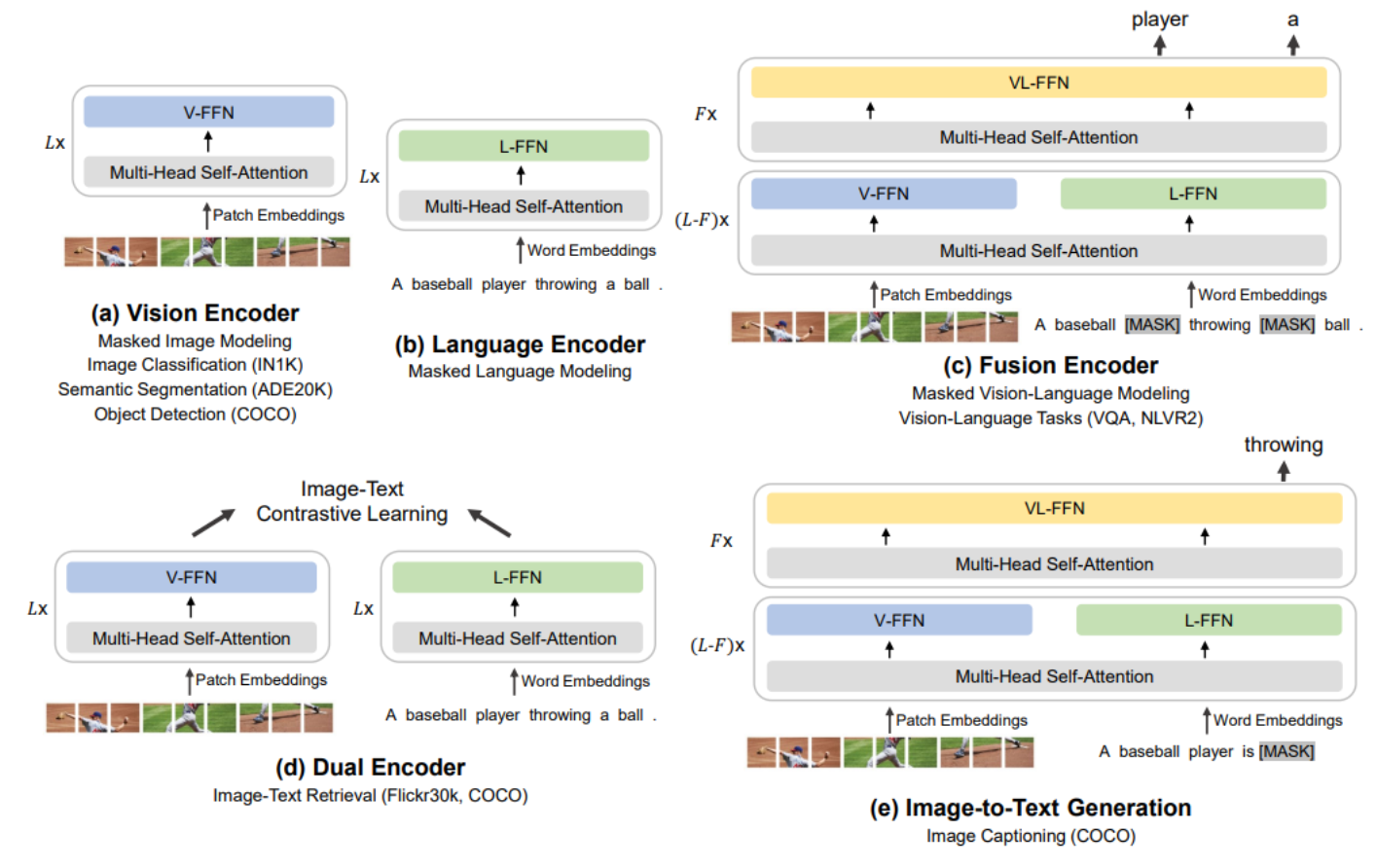
- 搭积木用于各种任务
近期工作
LISA(CVPR2024)
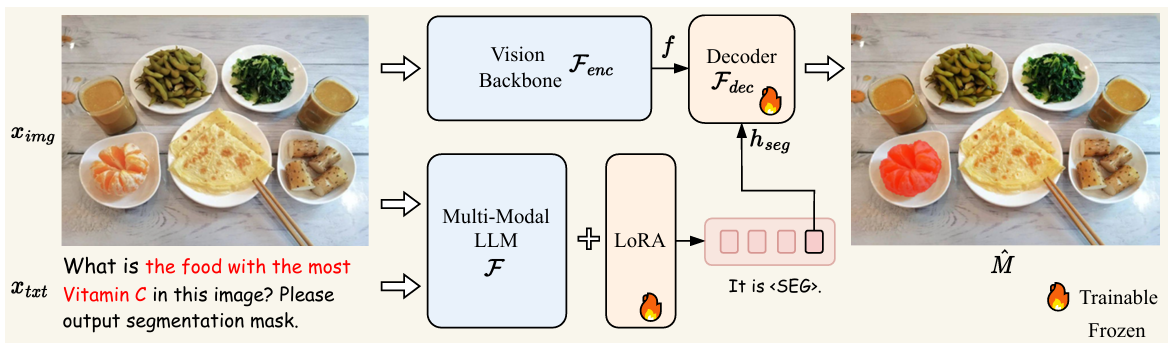
- 分类:VLM迁移学习
- 将掩码嵌入大模型的回答(SEG Token)
- 解决的问题:现有的模型需要人类显式的指示目标物体来完成视觉识别任务,对于隐式的指令不能理解人类的意图。推理能力对于工业应用尤其是机器人至关重要。
- 贡献:
提出推理分割任务,模型需推理出指令中的暗示进行分割任务,联合LLM和视觉任务
LISA模型 在无推理数据集上训练,在239个包含推理的例子上微调
建立一个推理分割基准 - 损失函数:
CE:cross-entropy 交叉熵 - 训练细节:
- 语义分割数据集:只包含图片和类标签。训练阶段随机选择每张图片上的几个类产生符合视觉问答的数据。如输入“USER:<image> can you segment the {class name} in this image?ASSISTANT:It is <seg>.”
- 参考图像分割数据集:包含图像和对目标物体的显示简短描述。输入“USER:<image> can you segment {description} in this image?ASSISTANT:It is <seg>.”
- 视觉问答(VQA)数据集:保持MLLM的原始视觉问答能力。
- 在239个包含推理的例子上微调。
RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback(CVPR2024)
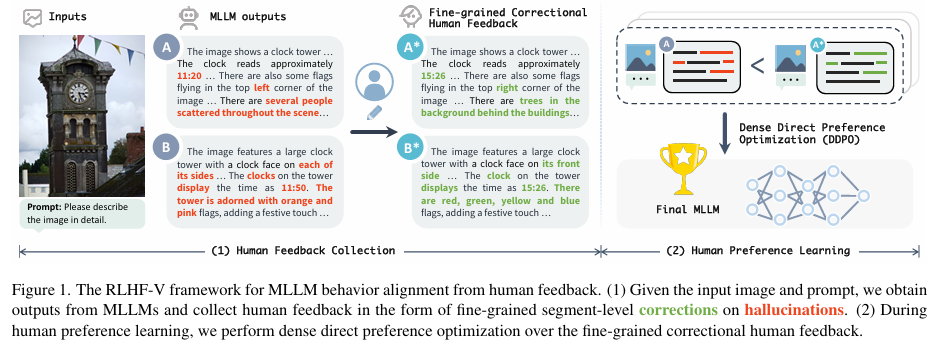
- 分类:VLM预训练
- 解决的问题:现有MLLM的行为没有对齐人类偏好,容易产生幻觉问题——回答没有事实依据。原因是缺少人类反馈。
- 方法:对齐MLLM的行为通过从人类反馈(human Feedback)学习
- 有关人类反馈的问题:
- 注释歧义(annotation ambiguity)回复太长,都有问题,人类不能显然的判断哪个回答好;即使能判断也不知道最优回答应该是什么样的
- 学习效率 粗粒度排名反馈不足以让模型学到理想行为,易导致奖励黑客攻击
- 解决方法:
- 数据层面:让人类修正者直接修正输出的幻觉段落(细粒度分级修正),产生最优响应作为,原始输出为,而不是生成两个回答让人类判断
- 方法层面:使用密集直接偏好优化(DDPO)
![[Pasted image 20250312113535.png]]
DPO:强化学习技术,通过直接比较两个候选动作的偏好数据优化策略模型(稳定、高效),对于RLHF(来自人类反馈的强化学习)(复杂,不稳定)的优化
![[Pasted image 20250312113557.png]]
DDPO:对DPO中进行改进,使修改过的部分具有更高的评分,加入一个正则化因子防止长回答高分。(使修改过的部分具有更强的人类偏好反馈)
Do Vision and Language Encoders Represent the World Similarly?(CVPR2024)
本文旨在探究单模态视觉与语言编码器是否对现实世界具有相似的语义表示。尽管像CLIP这样的对齐模型通过联合训练实现了跨模态匹配能力,但未经联合训练的单模态编码器(如仅针对图像或文本训练的模型)是否在潜在空间中存在语义对齐仍是一个开放问题。研究发现,即使未经对齐训练,这些编码器的表示空间仍存在显著的语义相似性,但其结构差异需要有效的匹配方法才能利用。
- 为解决上述问题,论文提出两种无需训练的匹配方法,利用语义相似性实现跨模态潜在空间的零样本对齐:
- 基于快速二次分配问题(QAP)的全局匹配
- 核心思想:将图像和文本的嵌入空间视为图结构,通过最大化二者之间的CKA(Centered Kernel Alignment)相似度,将匹配问题转化为图匹配优化问题。
- 优化目标:寻找最优排列矩阵,使得对齐后的图像与文本嵌入的CKA值最大。
- 加速策略:采用“种子图匹配”(Seeded Graph Matching)算法降低计算复杂度,利用部分已对齐的基准样本(base set)引导全局匹配。
- 基于局部CKA的检索与匹配
- 核心思想:通过局部CKA度量,计算查询样本与基准集之间的语义一致性,实现细粒度检索。
- 具体实现:将查询样本与基准集拼接后计算全局CKA,通过局部CKA分数评估匹配质量,利用线性分配算法完成匹配。
- 基于快速二次分配问题(QAP)的全局匹配
- 辅助技术:
- Stretchin:通过特征维度的方差归一化,增强嵌入空间的区分度。
- Clustering:对基准集进行聚类采样,确保覆盖多样化的语义范围,提升匹配鲁棒性。
Efficient Vision-Language Pre-training by Cluster Masking(CVPR2024)

- 分类:VLM预训练
- 解决的问题:
这篇论文主要解决了视觉-语言预训练(Vision-Language Pre-training, VLP)中的两个关键问题:- 效率问题:图像中存在大量冗余信息,导致大规模训练时计算成本高、速度慢。
- 表示质量限制:现有方法(如随机掩码)缺乏对语义结构的针对性,而语义掩码方法依赖复杂的分组机制,增加了计算负担。
- 其核心创新点包括:
- 聚类掩码策略:(受MIM启发)提出基于原始像素值或浅层嵌入特征的视觉相似性聚类方法,随机掩码成簇的图像块。这种方法无需复杂的语义分组模块,直接利用简单视觉特征(如RGB值)快速形成相似块簇,既减少计算量,又通过上下文推理增强模型对语义结构的理解。
- 高效性与有效性平衡:在保持高掩码率(如50%)的前提下,显著提升训练速度(相比CLIP提速36%),同时在下游任务(零样本分类、图像文本检索、语言组合理解等)中超越FLIP、CLIP等基线模型。
- 多特征融合:结合RGB值与嵌入层特征进行动态加权聚类,利用嵌入层的空间位置编码进一步优化掩码区域,提升对语义结构的捕捉能力。
- 简化实现:通过单次K-Means迭代、自适应阈值调整等技术,避免复杂计算,确保方法易于集成到现有框架中(如ViT)。
实验结果表明,该方法在ImageNet零样本分类、MS-COCO检索等任务中平均提升2-5%,并在语言组合任务(如SugarCrepe)中减少“词袋效应”,展现了更强的语义关联推理能力。
LaVIT(ICLR2024)
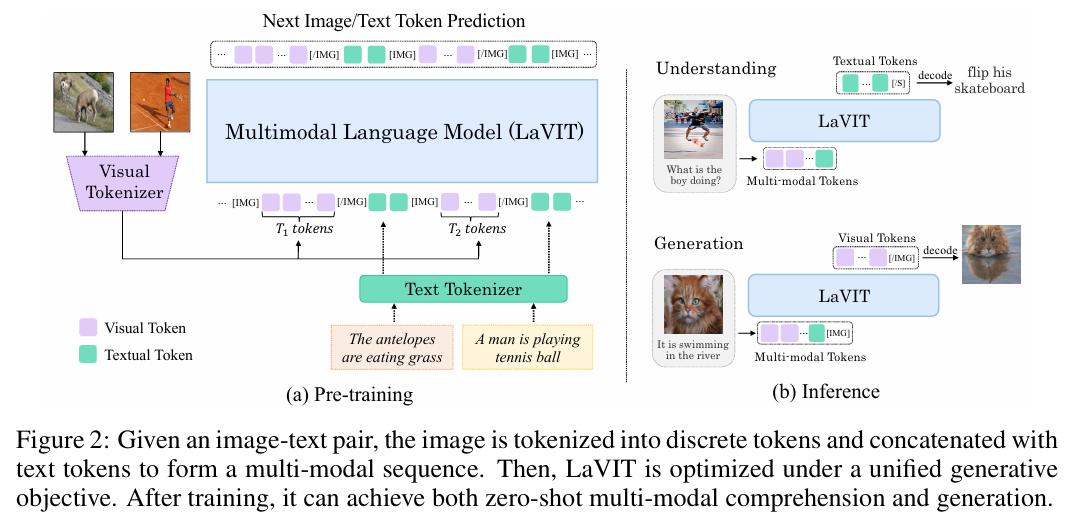
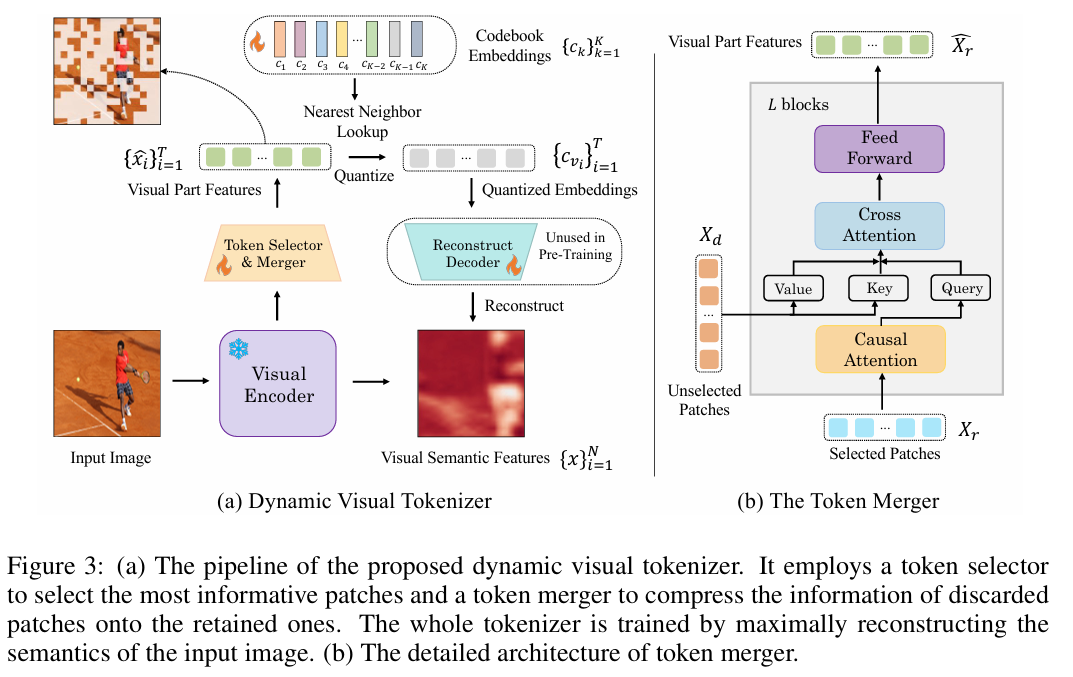
- 分类:VLM预训练
- 解决的问题:先前模型的训练目标聚焦于文本描述的生成,visual部分仅当做prompt,没有受监督。限制了模型的潜力让它们只能擅长于做理解任务。同时,很多模型将对齐任务交给适配器,没有用上LLM的交互能力。
- 方法:将文本和text token兼容->vison tokenizer
将视觉标记量化为离散的形式(像一门外语,能被llm理解),与llm预测下一个token的目标保持一致(预测下一个image/text token)实现any-to-any的跨模态理解和生成
动态token分布:图像的语义复杂度不同->不能使用固定长度的token编码图像(不经济、有累赘,语义信息高度相关,自回归任务不有效)。- selector:
决定哪个visual patch承载了语义信息
使用一个轻量化的多层感知机实现对分布的预测(1. 每个特征快得到一个1*2的输出表示保留/丢弃的概率2. 使用Gumbel-Softmax技巧采样(可微),选择概率较大的类别作为采样结果)
- merger:
将未选择的patch的语义信息根据特征相似性压缩到保留的patch上
使用交叉注意力机制(保留的patches提供Q,要丢弃的提供K和V)
- selector:
通过可学习的codebook将保留的visual token量化成离散的code(选择最近的code)
量化的特征c经过diffusion过程(decoder)重建图像计算损失(预训练不需要这步)
最终的tokenizer目标:(重建嵌入和原始嵌入尽可能接近,保留的token接近预设比率)
因为visual tokenizer,visual变成了一门”外语“,故训练变成了一个统一的目标:预测下一个image/text token
可不经过微调的进行多模态的理解和生成任务(文生图,图文生图,图图生图……)
Generative Region-Language Pretraining for Open-Ended Object Detection
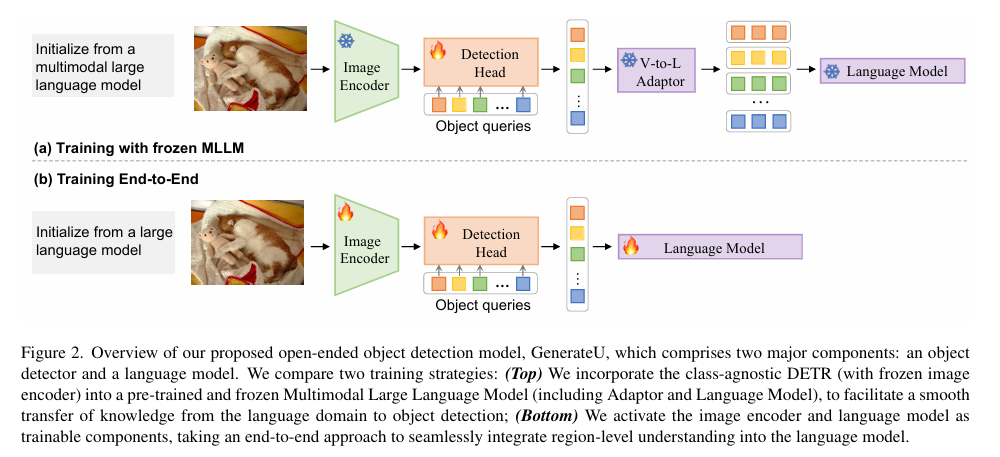
- 分类:VLM迁移学习
- 解决的问题:现有的目标检测(开放词汇目标检测、句子定位)需要在推理阶段给出预定义的检测目标
- 提出新任务:生成式开放目标检测
在推理阶段无需任何预先定义的类别知识,直接通过生成的方式自由输出图像中所有检测对象的名称 - 提出GenerateU模型,包含一个目标检测器(图像编码器+检测头)和一个语言模型(直接从MLLM得来)
目标检测器采用类无关目标检测器(Deformable DETR)提供目标候选,仅将目标分类成前景和背景 - 两种训练策略:
- 冻结解码器和MLLM,仅训练检测头 效果不好,原因是没有微调的MLLM使用图像文本对进行训练,生成的文本将整个图片作为条件,不能理解单个目标,存在域偏移
- 同时训练解码器,检测头和LM,视觉表示作为LM encoder的输入(仅保留匈牙利算法匹配成功的框),相关联的词作为解码器的生成目标,无缝的将区域层的理解送入LLM。
保留的object query首先通过一个映射对齐到llm的维度
AWT:Transferring Vision-Language Models via Augmentation, Weighting, and Transportation
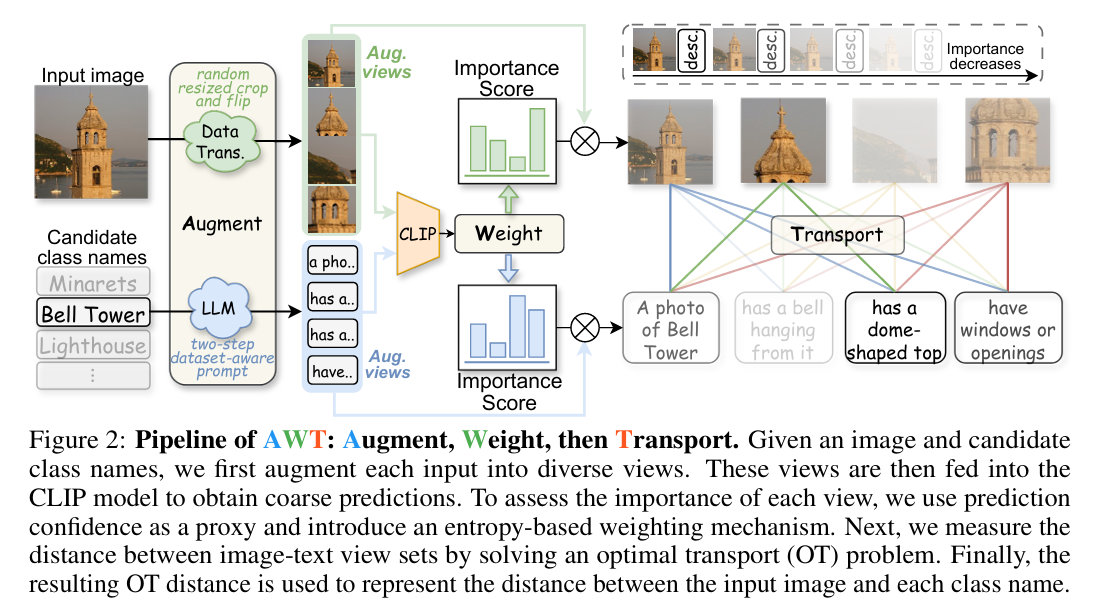
- 分类:VLM预训练
- 解决的问题:
- 大范围的预训练迫使VLM分析所有元素,缺乏关注特定感兴趣区域的能力
- 预训练将视觉描述与多样化丰富的文本描述关联,测试时仅使用类名不足以捕捉全部视觉范围
- 以往方法侧重于训练后提示(prompt learning),受限于训练资源
- 改进框架:提高CLIP的可移植性
- 增强输入(A)
图像增强:随机裁剪和翻转
文本增强:对类的细致描述->使用llm
同时增强两种模态
using a simple prompt like “Describe a {class}.”->描述笼统
使用CoT生成多样且相关的数据
问题:裁剪的图片对识别类的贡献不一样、一些描述和裁剪的图片有直接的相关性
使用AWT框架解决这些问题 - 动态加权输入(W)
动态的查看每种模态的重要性
使用预测熵(prediction entrpy)
计算文本嵌入(每个类的m个增强文本对应的嵌入做平均)和增强图片嵌入(n张)的相似性(使用CLIP),然后用熵的形式表示(为CLIP预测图片属于第i类的概率)低熵意味着高置信度(图片表示的东西越精准,分数越高)
计算llm生成的描述性文本(m个)和原始图片(1张)的相似性
计算重要性分数 - 最优传输(T)
为每个视图评估的重要性决定了其相应沙堆的质量,并使用余弦相似度计算距离(越像的距离越近)
将图片和文本的配对转换为最优传输问题->最小的成本将“沙子”从一个模态运到另一个模态,原图X属于第i类的概率为:
,其中和由生成,为最优传输的一个解法(Sinkhorn’s Algorithm)
- 增强输入(A)
CLIP负责计算图像/文本的重要性->让增强图像和最相关的增强文本的嵌入尽可能接近
FALIP: Visual Prompt as Foveal Attention Boosts CLIP Zero-Shot Performance(ECCV2024)
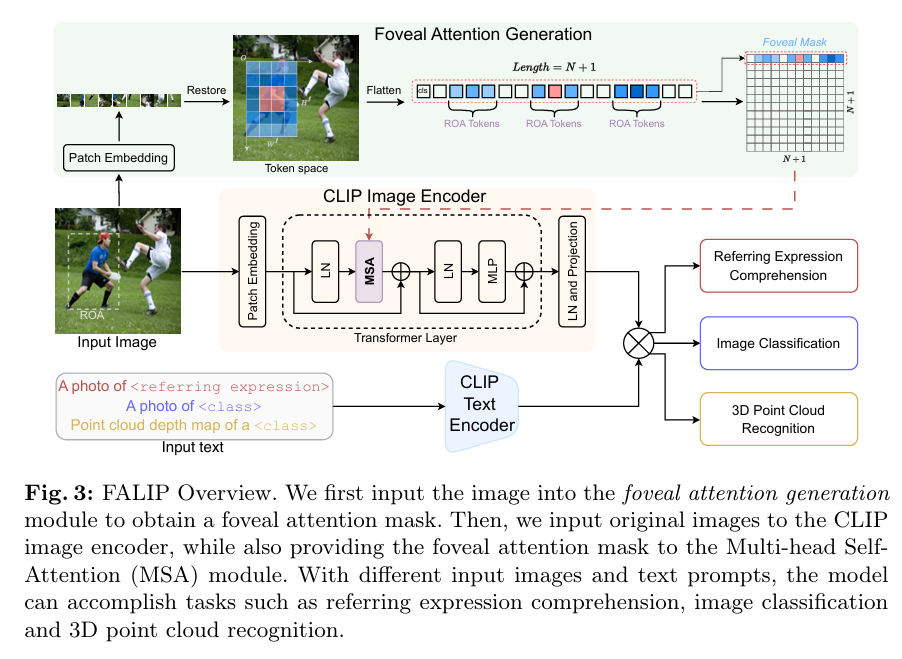
分类:VLM迁移学习
- 探究visual prompt的作用机制,以对视觉提示的有效性有原则上的理解并提出更有效的策略
模型会注意被标记的区域 - 其他方法:对原始图像做出改变(颜色块、裁剪、圈、掩码)
危害:会破坏细节,影响模型性能 - 本文方法:受人体视觉机制的启发,加入Foveal Attention,即插即用,不需要训练(attention prompt)
中心区域得分高,边缘低,不需要注意的地方得分为0
VIVL
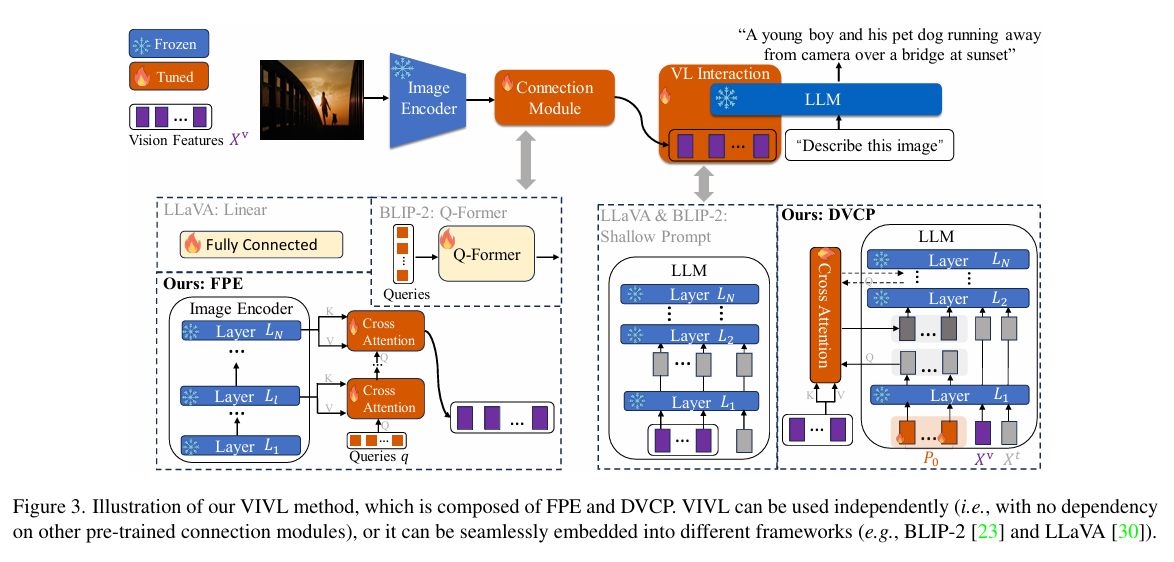
- 分类:VLM迁移学习
- 问题:
- 许多先前工作只使用image模态的最后一层特征,没有对表层特征的应用
- 先前工作vl交互比较浅(将图片特征作为prompt输入llm)
- 提出的两个模块:
- FPE(Feature Pyramid Extractor):提取image模态的表层特征
上一层的输出作为q和本层做cross attention - DVCP(Deep Vision-Conditioned Prompt)
每层都和图像特征做cross attention
cross attention为所有层共用,减少参数
仅在第一层使用可学习prompt(),其他层用前一层的输出
- FPE(Feature Pyramid Extractor):提取image模态的表层特征
GalLoP: Learning Global and Local Prompts for Vision-Language Models(ECCV2024)
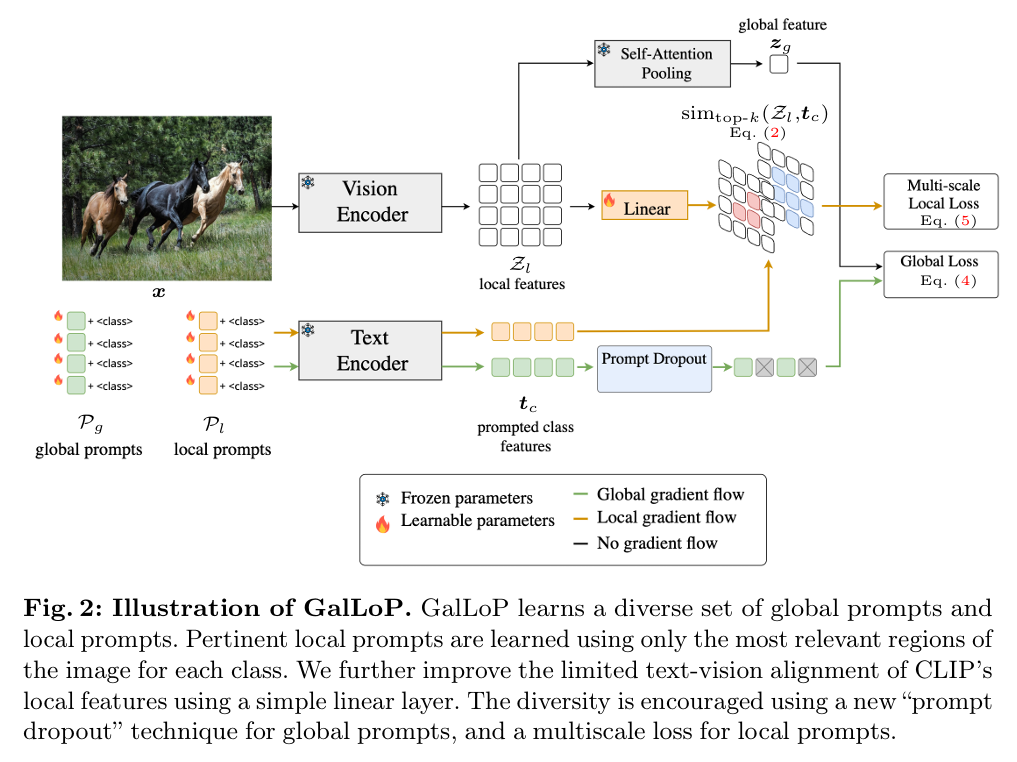
- 分类:VLM迁移学习
- 相关概念:
- OOD(out-of-distribution )detection:分布外检测,将两个语义信息相差较大的两个数据集构成ID和OOD,检测OOD样本(二分类问题)
- domain generalization:域泛化,从一个或几个不同但相关的数据集上训练一个模型,在unseen测试数据集上有很好的泛化
强调模型在面对不确定性时的容错能力
- 方法:指令微调,在class name前加上n个可学习的局部prompt和m个全局prompt
- 解决的问题:先前工作会在准确率和鲁棒性上寻找折中(分类准确率高的模型OOD和域泛化表现不好),本文提出的方法既有准确性又有鲁棒性
- 创新点:
- 有效的局部指令微调:通过稀疏的图像区域对齐局部prompt,有助于图像文本对捕捉细粒度语义
CLIP关注全局的图像-文本对齐,导致图像分类任务表现不佳。本文通过最大化前k高的局部图像特征-局部prompt特征相似度,使模型专注于相似度高的区域,减少背景噪声
local prompt learning:取相似度最高的k个区域取平均作为“距离”
然后就可以用CE loss了
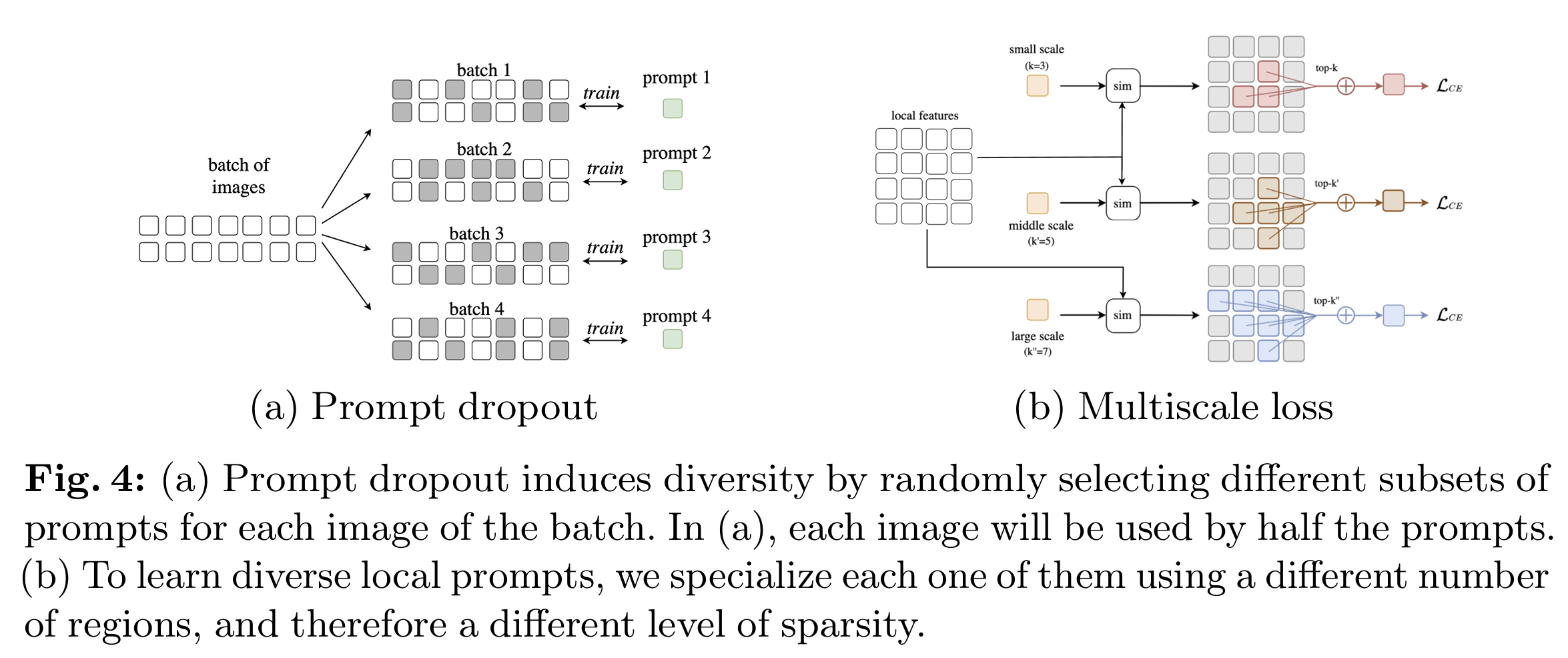
global prompt learning:采用dropout机制,其他同对比目标
不同的local prompt采用不同的k以学习不同范围的特征 - 提高聚合多样性:学习全局prompt对齐全图和局部空间定位prompt,使用“prompt dropout”策略提高它们的多样性。在训练中随机的丢弃一些全局prompt来防止过拟合及避免引入额外的loss
- 有效的局部指令微调:通过稀疏的图像区域对齐局部prompt,有助于图像文本对捕捉细粒度语义
RegionGPT: Towards Region Understanding Vision Language Model(CVPR2024)
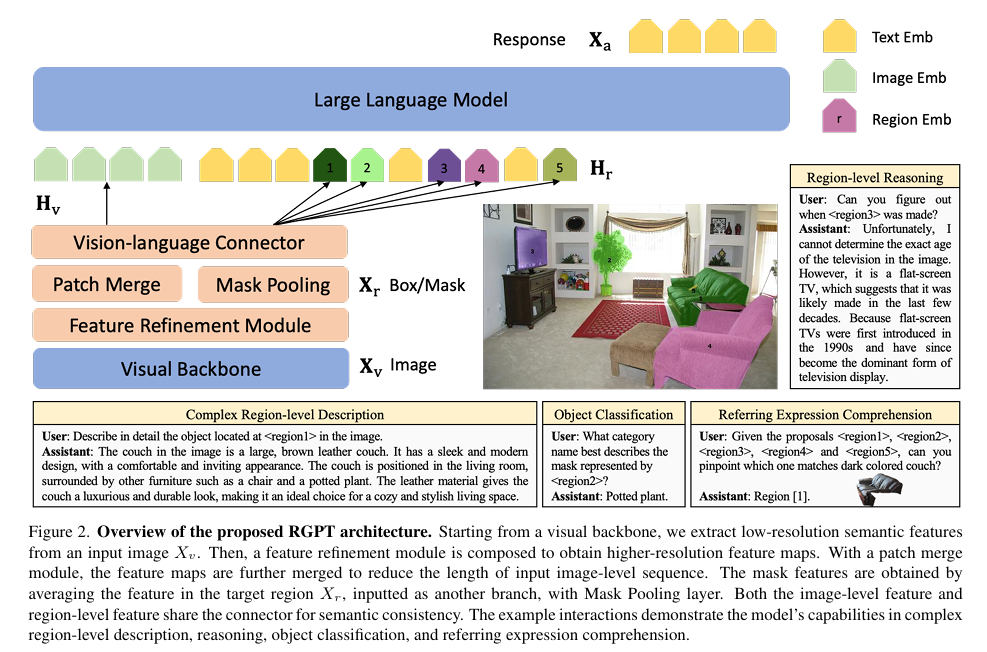
- 分类:VLM迁移学习
- Region-level Vision Language Model
- 解决的问题:先前工作依赖语言解码器去解释位置信息(输入坐标,让text端增加区域兴趣),本文使用一个专用的视觉空间感知模块捕捉区域性的特征
- 部件介绍:
- 视觉主干:使用CLIP的ViT-L,权重冻结,提取低精度的特征图
- 特征提炼模块:获得高分辨率特征图,使用反卷积将特征图扩大4倍
- 使用mask pooling提取每个区域的特征(将mask区域的特征取平均)
- patch merge:使用自适应池化层(函数自己计算核大小和步长)将高分辨率特征图池化至目标大小(高分辨率特征图序列化后较长,增加开销)
- Vision-language Connector:一个MLP,将图像特征映射到LLM的词嵌入空间,全图层次和区域层次的特征共享同一MLP以获得语义一致性
VisionZip: Longer is Better but Not Necessary in Vision Language Models(CVPR2025)
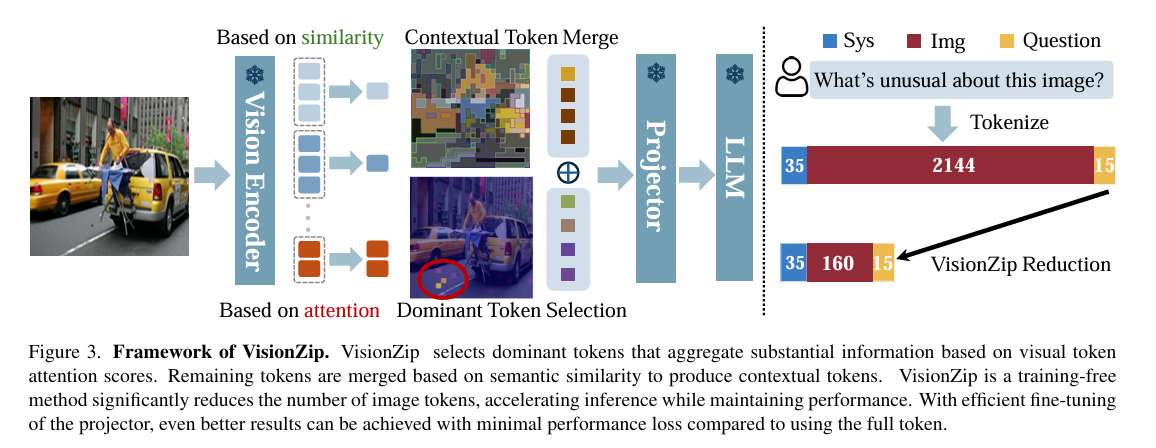
- 分类:VLM迁移学习
- 解决的问题:vlm的表现依赖于visual tokens的增多(vt数量远高于tt),但这样会消耗内存和计算资源,阻碍vlm在某些场景上的应用,不是所有visual token都是有效的(image的语义比text稀疏)
- attention只关注很少的visual tokens,压缩送入llm的visual tokens数量
- VLM结构:一个视觉编码器,一个模态映射器(将视觉tokens对齐到llm的词嵌入空间)和一个llm
- VisionZip:
- 选择占支配地位的token
选择第23层(随层数加深注意力逐渐集中,但由于CLIP要做对比任务,最后一层的注意力反而下降,故选倒数第二层计算注意力分数)
有cls token的(如CLIP)利用cls token的分数识别关键visual tokens;没有cls token的(如SigLIP)计算每个token从其他所有token接收到的平均注意力 - 上下文token融合
融合非主流的tokens,划分目标token和要融合的token,利用key计算相似度(点乘),将要融合的token合并进最相似的目标token
- 选择占支配地位的token
Words or Vision: Do Vision-Language Models Have Blind Faith in Text?(CVPR2025)
- 分类:其他
- 当图片模态和文本模态出现偏差时,vlm会偏向于相信文本模态
- 文本变量:符合,冲突,不相关
- 模型行为:和文本相关,和图片相关,都不相关
- 定义文本偏好度(TPR):
考虑文本和图像不一致的情况,,指回答偏向txt模态的比例,指回答偏向img模态的比例 - 宏准确率:
文本变量为符合、冲突、不相关时模型回答准确率的均值 - 标准化准确率:
准确率除以一个在base set上计算所得的准确率,度量模型受text变量的影响程度 - 使用gpt构建text变量
- 结论:
- 存在对文本的盲目相信行为
- 文本偏好越强的遇到有害文本时性能下降的越明显
- 会导致安全风险
- 影响因素:
- 指令能减少文本偏好但有限(显式要求模型关注图片模态)
- 使用更大参数的模型能减少文本偏好
- 模型容易受似乎相关的文本的影响而不易受完全无关的文本的影响
- 文本偏置受image token和text token顺序的影响
- 模型偏向更高确定性的那个模态
- 解决方法:
- 指令中加入“focus on the image”
- 有监督微调
- 理论分析:模型依赖于预训练语言模型(纯语言数据远大于多模态数据)
self-instrospective decoding:alleviating hallucination for large vision-language models(ICRL2025)
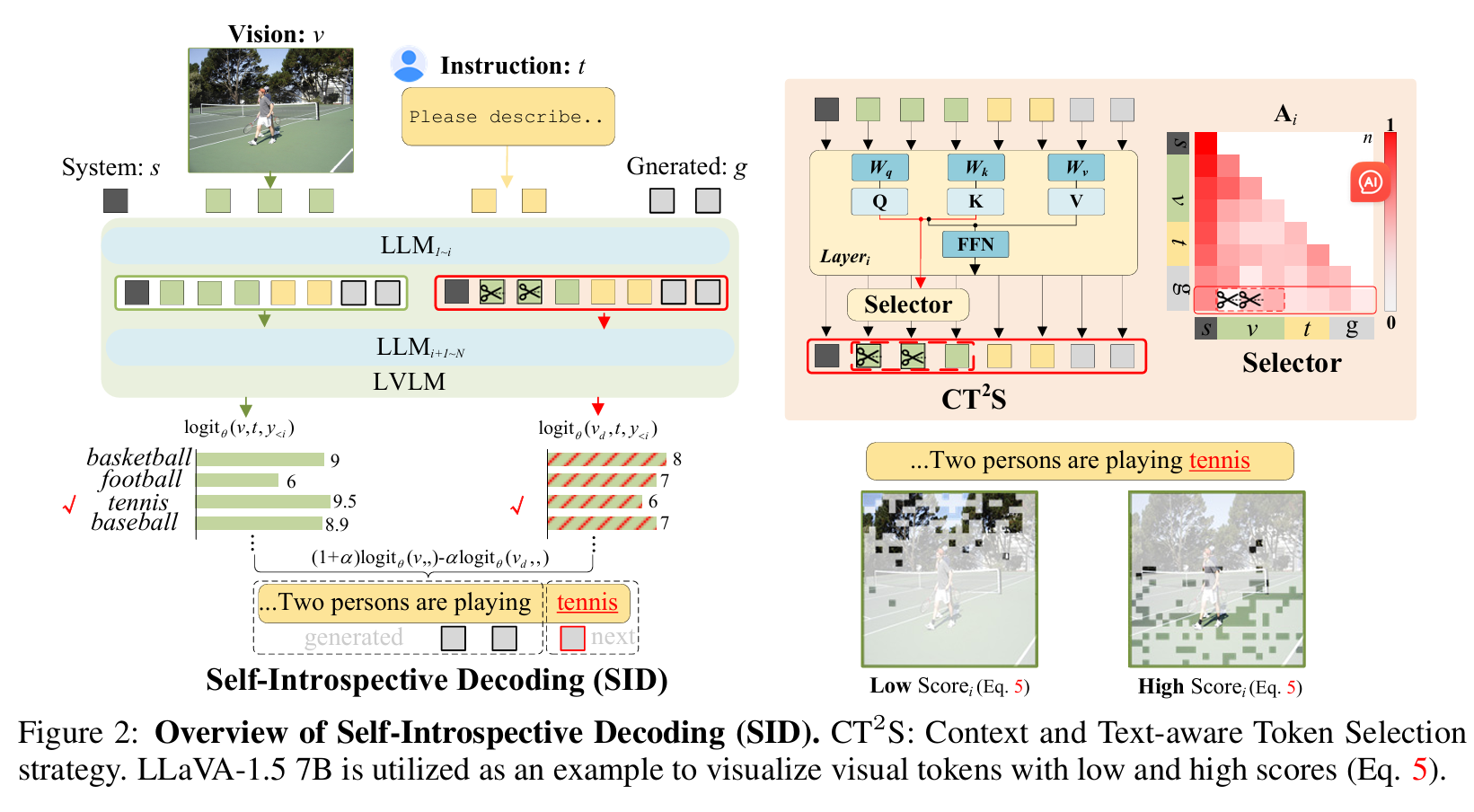
- 解决LVLM的幻觉问题
- 幻觉:生成不相关、事实错误、无意义的文本
- 先前方法:
指令微调、事后推理、解码策略- VCD(Vision Contrastive Decoding)
将原始图片和失真的图片传入LVLM,失真的图片更容易造成幻觉。选择相信原图结果而拒绝失真图的结果。 - ICD(Instruction Contrastive Decoding)
将原始prompt和负面prompt传入LVLM,负面prompt更容易造成幻觉。选择相信原始prompt的结果而拒绝负面prompt的结果。
- VCD(Vision Contrastive Decoding)
- 缺点:推理时双倍的开销、需要复杂的设计,不一定放大预期的幻觉反而会引入新的不确定性
- 本文提出的方法:SID(Self-Instruction Decoding)
- 模型能通过先前的token自我评价视觉重要性
- 使用llm的注意力机制进行评分,保留分数低的10%视觉tokens,使用VCD同款方法减去幻觉高的部分
- 测试在ve阶段,第i个llm层使用select机制的效果,发现在i=3时保留10%的visual tokens效果最好(太低没有text模态的影响,太高模态融合已经完成)
- 保留得分高的,使用加法好不好?不行,减法联系了同时发生的目标,提高了它们的logit分数,然后减掉它。加法只让目标得分更高,在对抗的环境下表现不好。
Mind the Interference: Retaining Pre-trained Knowledge in Parameter Efficient Continual Learning of Vision-Language Models(ECCV2024)
- 持续学习:序列的学习不同的任务,不会忘记以前学过的知识
- 最近工作:
- ZSCL:引入大规模数据集进行知识蒸馏,结合权重集成方案,现实难以实现
- 参数有效:利用指令微调,会扰乱预训练知识,降低zero shot能力
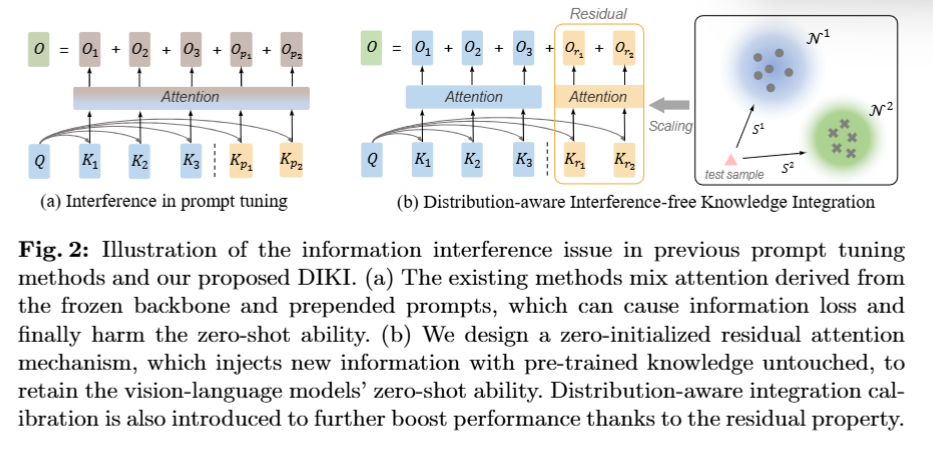
- 提示学习(prompt learning)a图:
为每个任务学习和储存一组轻量级的提示,在持续学习阶段形成一个“提示池”,推理时将学习好的prompt附在原嵌入前来恢复学习的知识
选择prompt:最大化余弦相似度或聚类算法
缺点:扩展的prompt和输入相互影响,导致信息丢失 - 提出的方法:分布感知的无干扰知识集成(DIKI)b图:
- 残差注意力机制
分别计算input tokens的自注意力和 prompts和input的交叉注意力。即训练一个剩余的注意力分支而不改变现有注意力。学习的知识通过加法引入输出。持续学习阶段更新K和V。
输入序列长度不变,没有引入prompt参数。预训练阶段强制0初始化V,随机初始化K - 通过分布校准融合
为每个任务维护一个高斯分布,对于输入使用得分得分越高表示样本最有可能从什么任务中抽取。若所有得分都低,样本从新的分布中抽取,利用最大得分来加权剩余注意力输出
为不熟悉的图像分配较低的权重保留vlm的预训练zero shot能力
- 残差注意力机制
Open-Vocabulary Object Detection via Language Hierarchy(NIPS2024)
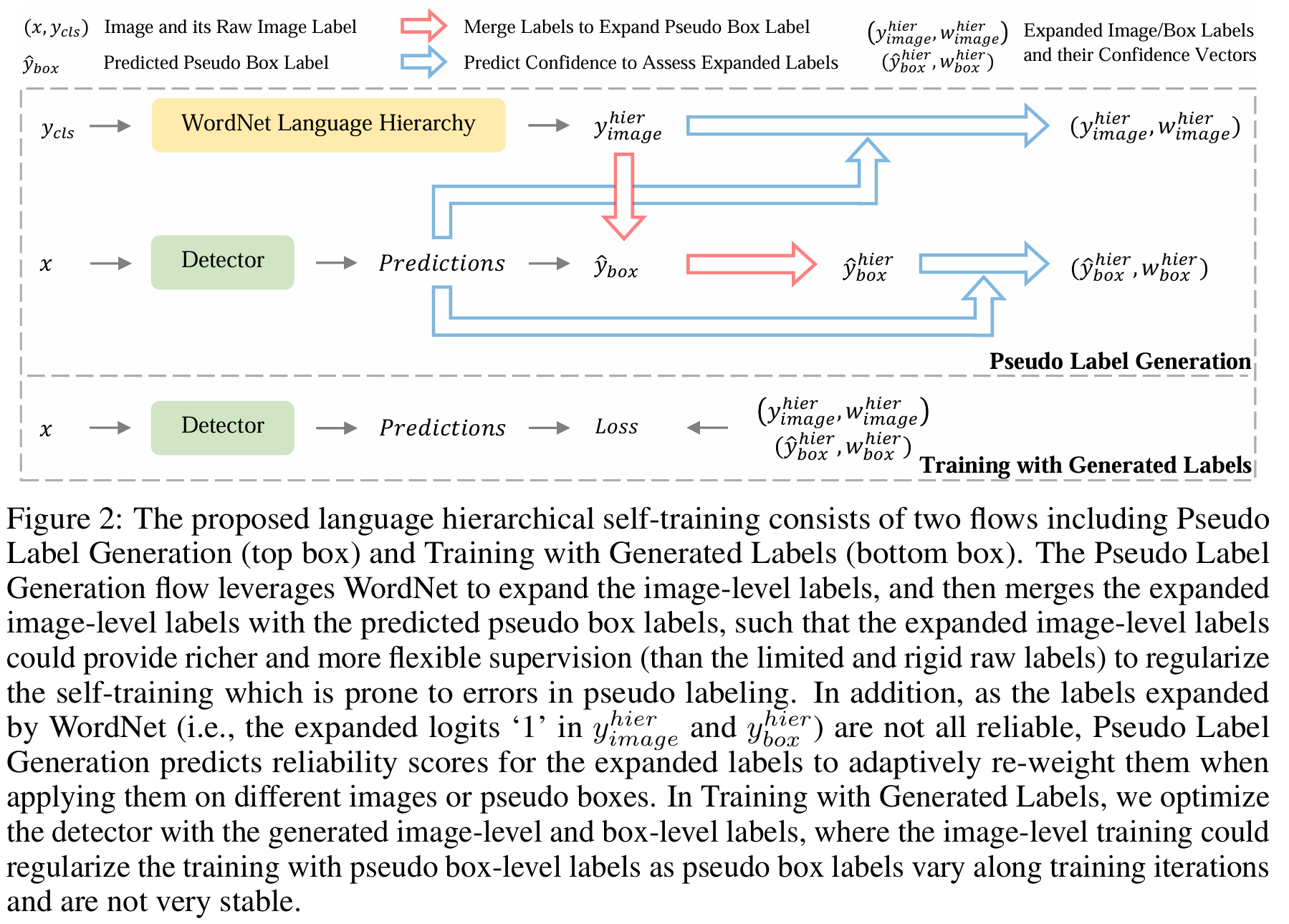
- 分类:为了目标检测的VLM知识蒸馏
- 解决的问题:数据集提供的图像层次的标签不具有精细的目标信息,最近的研究聚焦于各种从图像到框的分配策略,存在受原始图像层面标签限制和标签失配问题
- 弱监督目标检测:标签比任务弱(目标检测任务只提供样本类别标签)
- 创新点:
- 使用语言分级扩展图像层次的标签
- LHST(Language Hierarchical Self-Train):标签失配来源于分级的模糊(水生哺乳动物/海豹),故使用语言分级扩展标签(将上位词和下位词全变成标签)。但扩展的标签不都是可靠的,故通过自训练方法提供置信分数(预测属于该类的概率(如果伪标签和扩展标签不同))。自训练使用的伪标签存在噪声损害训练,使用扩展标签实现更丰富和灵活的监督。伪box label(框的类标签)在训练阶段经常变化,使用图像层次的loss做一个正则。
- LHPG(Language Hierarchical Prompt Generation):弥补训练数据和测试数据的词汇表差异。使用CLIP的language encode测量测试词汇和同义词的嵌入距离(做同义词替换)。测试集的词汇表被WordNet标准化了
F-LMM:Grounding Frozen Large Multimodal Models(CVPR2025)
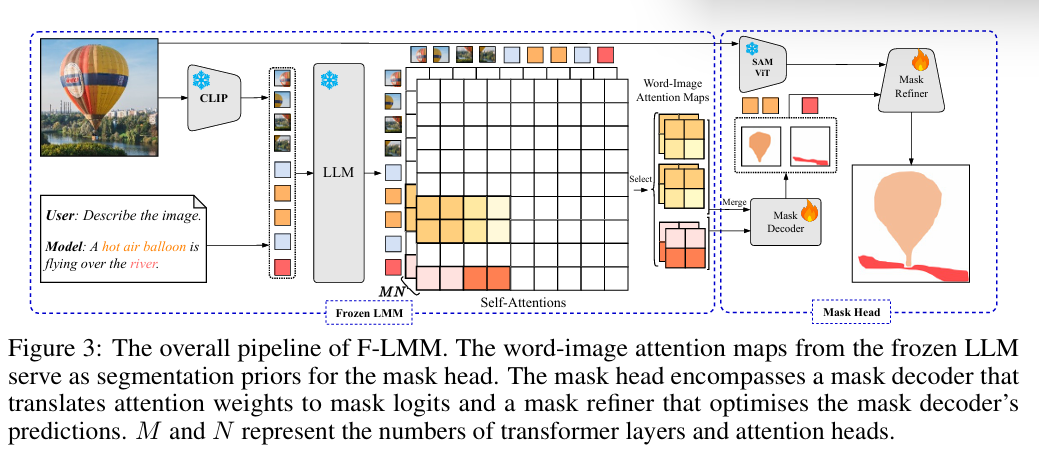
- 分类:VLM迁移学习
- 解决的问题:现有的LMM通过微调使模型产生<seg>token来处理目标定位能力,会破坏原始模型的交流能力
- 创新点:将冻结的LMM中的词语-图像注意力图转换成定位掩码,完美保留原始的交流能力
- 模型架构:
- 模型回答产生后,将图片经冻结的CLIP图像解码器和生成的回答输入冻结的LLM。
- 提取目标对应的词元对所有图像tokens的注意力分数,恢复为2D注意力图(M层N个注意力头的所有attention map),传入mask head
- mask head由能训练的mask decoder和mask refiner和冻结的SAM ViT构成。mask decoder使用U-Net,负责将attention map转化成mask logits,使用BCE和DICE为loss。mask refiner(SAM架构)的输入为:原图经SAM的image encoder得图片嵌入、mask head的输出经SAM的prompt encoder的稠密prompt嵌入、的框作为框嵌入、目标的text嵌入作为稀疏prompt嵌入。image embedding和稠密和稀疏的prompt emdedding输入mask refiner以获得细粒度的掩码预测。
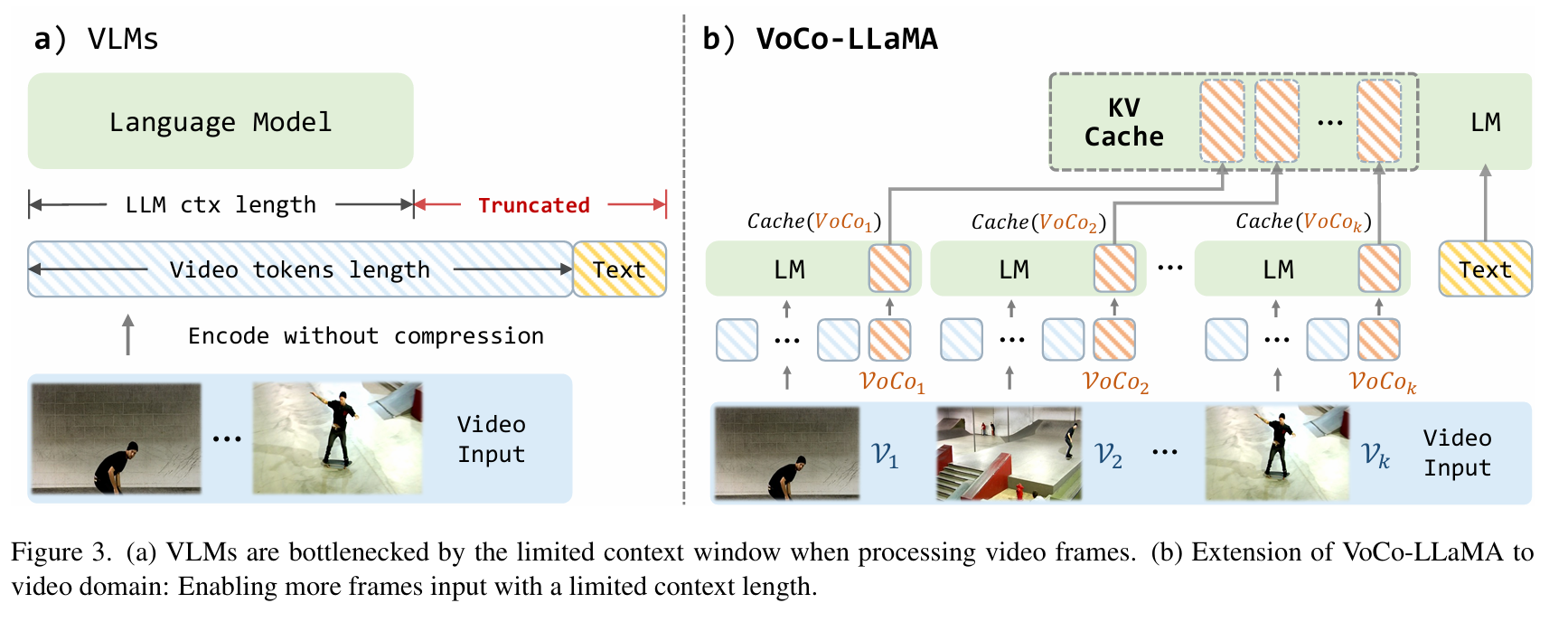
VoCo-LLaMA: Towards Vision Compression with Large Language Models(CVPR2025)
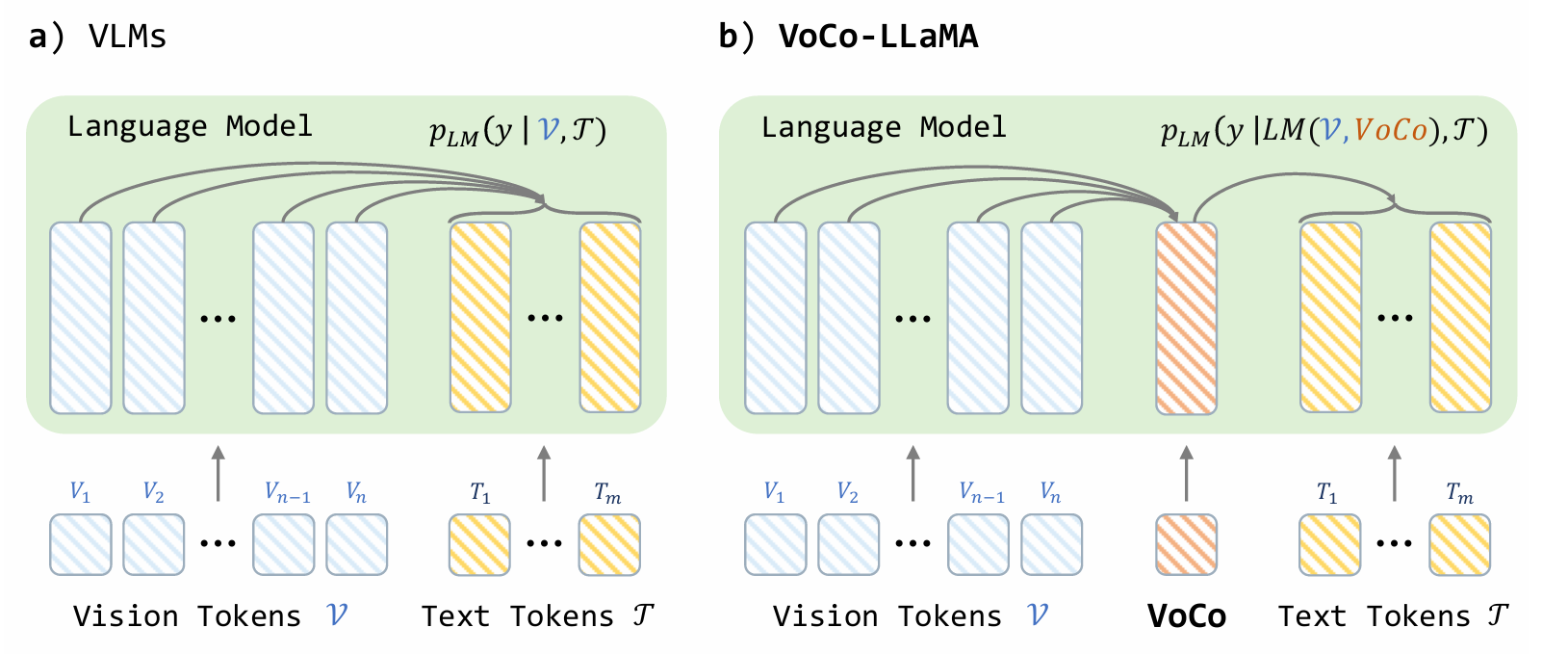
- 分类:VLM蒸馏
- 解决的问题:llm输入的token是有限的的,大量的visual tokens占领了宝贵的上下文窗口
- 解决方法:使用LLM的内在能力压缩visual tokens
- 训练方法:新建一个特殊的token VoCo,输入变为(V,VoCo,T),使用掩码实现VoCo只能注意前面的vision tokens ,text tokens只能注意前面的VoCo token
- 产生方法:
- 适用于视频理解:原始方法容易超长,VoCo_LLaMA提取每个帧的特征存入KV Cache,处理完帧后一同和text输入llm完成任务
Mitigating Hallucinations in Large Vision-Language Models via DPO: On-Policy Data Hold the Key(CVPR2025)
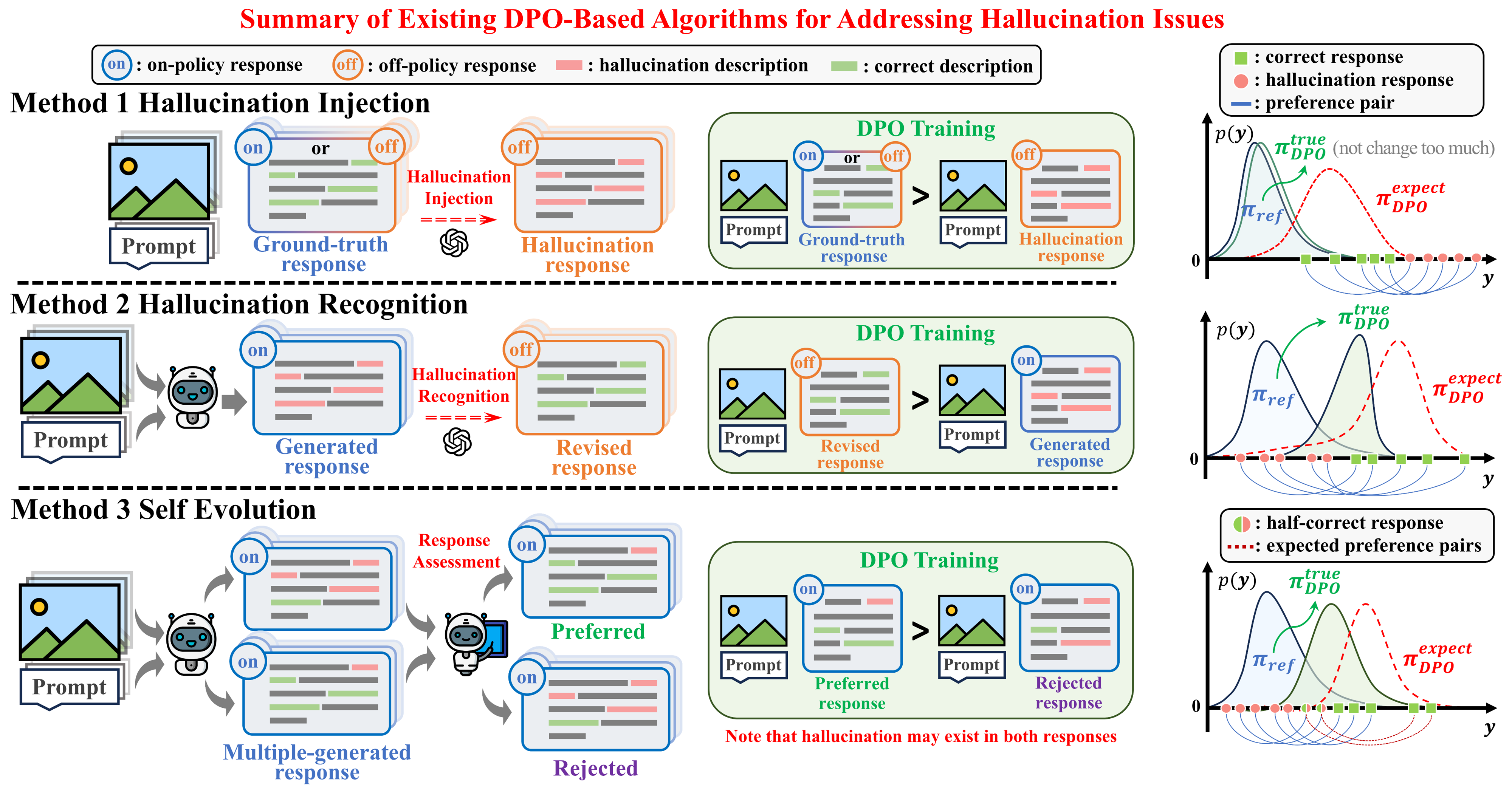
- 模型分类:其他
- 解决的问题:处理VLM的幻觉问题(对DPO的改进)
- 创新点:
- 通过对DPO训练数据的构建发现DPO存在的缺陷
三种方法:幻觉注入类(人为注入幻觉片段)、幻觉识别类(使用专家反馈甄别模型输出中的幻觉,进行细致修改)、自我进化类(生成多个回答,使用导师模型判断幻觉程度进行排序)
理论上,第一类的幻觉不是模型产生的,第三类存在于多个回复中的顽固幻觉无法消除,第二类理应最有效
实验显示3>2>1
而时KL散度无穷大
原因:专家改动后的response,通常对于原模型来说,都是off-policy的(即时这些改动再微小也无济于事),那么我们根本无法指望这些专家反馈能被模型学会(产生梯度消失) - OPA(On-Policy Alignment)-DPO在DPO开始前将数据变成on-policy就行
方法:使用修改后的数据对模型进行SFT
- 通过对DPO训练数据的构建发现DPO存在的缺陷
VLM综述
http://zrj0926.github.io/2025/03/17/VLM综述/