从VAE到DDPM
VAE(变分自编码器)
从AE(自编码器)开始
AE的作用是什么?是为了得到样本的特征。为了实现这个目标,我们需要两个部件:encoder(编码器)和decoder(解码器)。编码器的作用是将图像降维以得到低维的特征,解码器的作用是将特征解码重建原图,以计算重建损失更新神经网络参数,确保编码器压缩原图得到的特征的正确性。
从AE到VAE
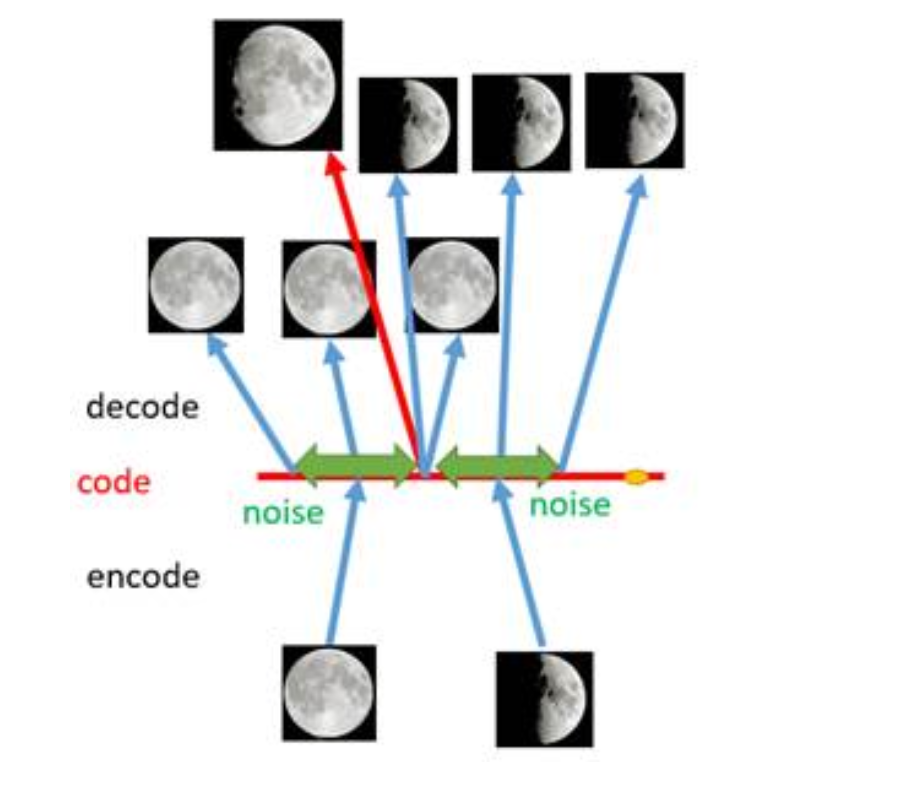
那么,能不能直接使用AE生成图像呢?显然是不行的。假设我们直接从AE的特征空间中随机取一个点,将其送进解码器解码,我们得到的大概率是乱码。这是因为编码器极易过拟合,它会将所有图片拟合成特征空间中的一个点。这意味着,假设我有两张图片——一张笑脸,一张哭脸。通过解码器解码,它们会被分别映射到特征空间的两个点1(笑)和-1(哭)。在这种情况下,只有当我恰好取到1和-1时解码器能解码出对应原图,而当我取0时,我只能得到乱码,因为解码器根本没有学习过这种特征表示。
VAE做了什么改进,使得图像生成成为可能呢?那就是通过编码器将图像编码成分布。这意味着图片的编码不再是一个定值而是一个范围,这个范围中的任意值都有可能成为这个图片的编码。因为在训练时是在编码得到的分布中随机采样,将采样得到的样本送进解码器重建图片计算重建损失的。举个例子,同样是一张笑脸,一张哭脸,我们将其编码成以1和-1为均值的两个分布,我们重这两个分布中分别随机采样,都有可能采样到0,这意味着0这个点能同时被解码成与哭脸相似和与笑脸相似。且因为分布意味着取每个点的概率是不同的,如0.5这个点在输入是笑脸的时候更容易被取到,故0.5这个点解码出的图像更接近笑脸。故我们能认为特征空间中的每一个点都是有意义的,这样就解决了AE的过拟合问题。使图像的生成成为可能。
此外还有一个问题,方差好比给图像加上一个高斯噪声,若神经网络的损失仅仅为重建图像和原图的像素差异,则会导致方差退化为0,这时候VAE就退化成了AE,同样是过拟合了。我们希望方差能持续存在,这就需要一个“正则化项”,让解码器解码出的分布近似正态分布,以使“噪声”持续存在。故损失函数为。
VAE的缺点
VAE的缺点在于生成的图像往往是模糊的,造成这种模糊的原因是:
- VAE降维-升维的过程存在细节的损失。降维得到的特征往往是一些低频的结构。而高频的细节往往被去除了。
- VAE采用像素级的图像损失使其倾向于输出平滑的结果。清晰的图片意味着更锐利的边界,这导致图像偏移带来的像素损失是很大的,即使这种偏移人眼不能察觉。故相比于0 1这种边界,VAE更倾向于0 0.5 1这种平滑的边界,这将导致图片的模糊。
DDPM
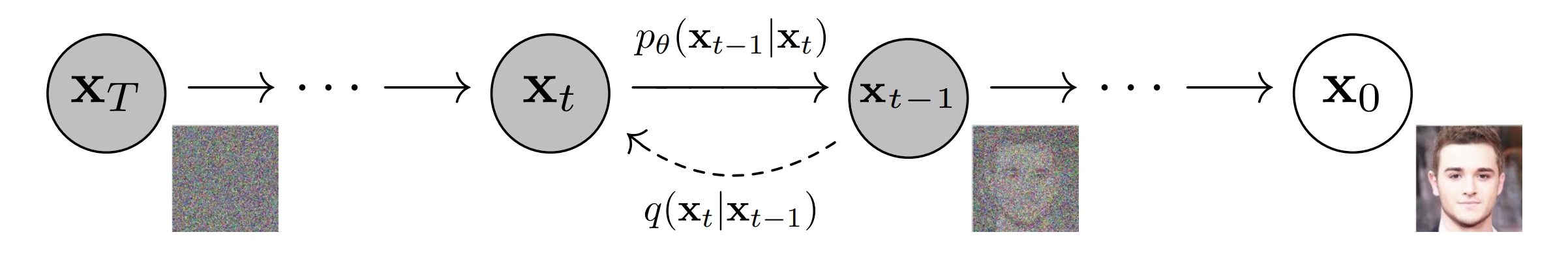
DDPM的灵感来自非平衡热力学,将图像的生成视作一个逐步去噪的过程。正向是扩散过程,为原图加上慢慢变强的高斯噪声,直到图片变成纯高斯噪声。反向为生成过程,使用神经网络预测每一步添加的噪声,让图片逐渐去噪,直到将纯高斯噪声恢复成清晰的图片。
一些问题
- 加噪过程可以写成,反向能否直接使用一步生成?
不能。DDPM能生成清晰图片的关键在于使用多次简单的概率分布采样拟合一个复杂的分布(真实图像的分布)采样。不可能一步就拟合出来,这样只能得到一个模糊的图像。 - 为什么均值和方差分别为和?
为了让增大时,均值趋近于0,方差趋近于1。 - 模型预测的噪声是什么?
本质上是一个分布的均值。
DDPM相较VAE的优点
优点在于能够生成更加清晰的图片,原因是:
- 预测的是一个时间步的噪声,类似于resnet网络的残差,相较于重建整张图片更容易实现,能逐步还原出细节。
- 多步预测概率分布。使用多次简单的概率分布采样拟合一个复杂的分布(真实图像的分布)采样。表达能力更强。
- 迟迟钟鼓初长夜,耿耿星河欲曙天。悠悠生死别经年,魂魄不曾来入梦。