VQ-VAE
前段时间看到一篇将visual tokens离散化(当成一门外语)送入LLM以此统一语言和视觉模态训练的文章,其对visual tokenizer的实现同VQ-VAE相似,故将VQ-VAE的视觉离散化方法记录在这里
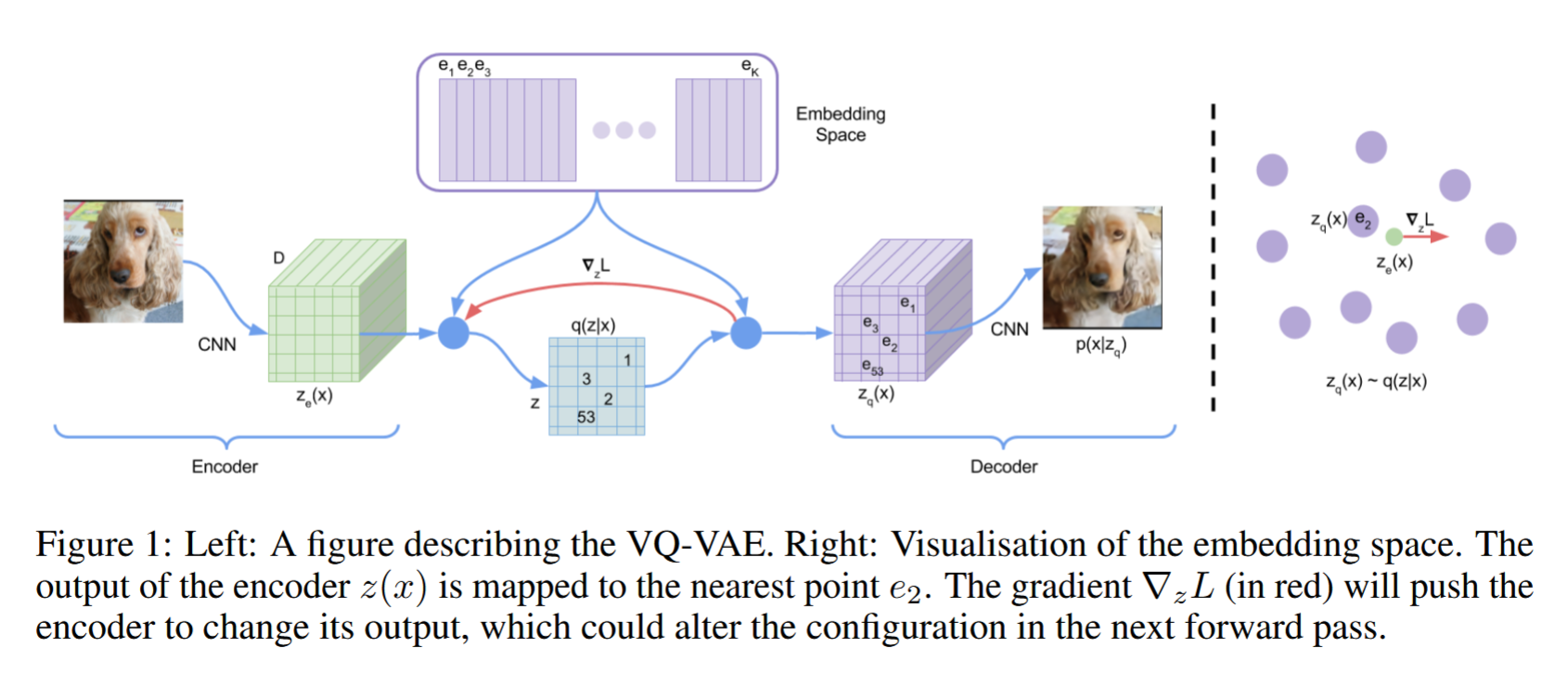
- 视觉令牌离散化的方法
- 三个组件:
- encoder
编码器,负责将图片压缩成低维的特征() - decoder
解码器,负责将离散化的特征()恢复成原图 - codebook
类似一个“词嵌入层”,负责把连续的特征离散化
- encoder
- 离散化过程:
假设和的维度为,codebook的维度为,即有个“单词”,每个单词对应维空间中的一个点。对中的个点,遍历codebook找到距离它最近的那个“单词”,这样就从到了 - 训练细节:
- 如何训练encoder和decoder
- 使用AE的loss:
- 问题:从到的过程是不可导的
- 解决方法:使用梯度复制
将的梯度复制给。使用STE(straight-through estimator)技术,前向传播(计算loss)和反向求导(计算梯度)可以不对应,即梯度可以被随意设计
基于此,VQ-VAE使用sg(梯度停止)运算(对应pytorch的(x).detach()),前向传播时,反向传播时,新的重建损失为:
前向传播时,使用计算误差,反向传播时,使用计算梯度
- 如何训练codebook
- 目标:嵌入空间的每一个向量能概括一类编码器输出向量,即嵌入空间向量要和对应编码器的输出尽可能近,loss为:
- 问题:编码器和嵌入空间的学习速度不应一样快
- 解决方法:采用停止梯度的技巧控制两者的学习速率
新的loss:
其中,用于控制编码器的学习速度。前一项为字典学习算法的经典算法Vector Quantisation,用于优化嵌入空间,后一项为分离损失,确保编码器的输出不会离codebook中的向量太远
- 总体损失函数为:
从左到右依次为:重建损失项、codebook更新损失项、分离损失项
- 如何训练encoder和decoder
- 如何实现图像生成
- 困难:不好采样
相较于VAE,VQ-VAE更像一个AE,将图像压缩成离散的向量(提供“大图像”到”小图像“(句子)的方法和”小图像“(句子)到”大图像“的方法)。由于VQ-VAE将图片编码到了一个离散的向量,在由离散向量构成的嵌入空间中采样是困难的。故VQ-VAE的图像生成不能像VAE那样直接从嵌入空间进行采样 - 解决方法:训练PixelCNN生成“小图像”
PixelCNN适合拟合离散的分布,从PixcNN采样生成“小图像”,再利用VQ-VAE的解码器将”小图像“恢复成”大图像“- PixelCNN采样方法:
- 初始化:从一个随机初始化的离散编码开始。
- 逐位置生成:对于每个位置,使用PixelCNN预测该位置的离散编码的概率分布,并根据这个分布采样得到具体的编码值。
- 重复直到完成:依次生成所有位置的离散编码,直到得到完整的离散编码矩阵。
- 解码:将生成的离散编码矩阵输入到VQ-VAE的解码器中,得到生成的图像
- PixelCNN采样方法:
- 困难:不好采样
VQ-VAE
http://zrj0926.github.io/2025/03/18/VQ-VAE/